读《High Performing Cache Hierarchies for Server Workloads》
背景
在介绍这篇论文前,先抛出一个问题:Intel平台Haswell到Skylake-SP一个比较重要的变化就是将原来的Inclusive Cache改换为Exclusive Cache,这种调整是出于什么考虑?所以不禁让人想像由于什么原因需要使用Exclusive Cache?当然微架构中的很多问题都是权衡。这篇15年的论文中介绍的背景以及实验就可以理解该演变的其中原因之一。当然先阅读“伴读:Ring Bus VS Mesh”节开胃也未尝不可。
一段Inclusive Cache与Exclusive Cache描述:
- 包含式Cache(Inclusive Cache):拿L1 L2来举例说明,L1的数据一定在L2中,但L2中的数据不一定在L1中。优点是设计复杂度低,是一个天然的Snoop Filter,缺点是会造成空间浪费,需要保证L2/LLC比例;
- 独占式Cache(Exclusive Cache):L1和L2中的数据不重叠。设计复杂,同时需要单独设计一个模块充当Snoop Filter;
- 非包含非独占 NI/NE(Non-inclusive Non-exclusive):没有绝对的Exclusive Cache,表达成Non-inclusive Cache更准确些。
关于NI/NE较详细的说明,这里有一份资料可以参考:http://yuhaozhu.com/CacheMemory.pdf
论文摘要
applications whose working set is larger than the smaller caches spend a large fraction of their execution time on shared cache access latency.
比L2 Cache容量大的应用花了大量的执行时间在LLC上(看上去访存瓶颈就从memory转移到了LLC上)。
The consequence of increasing the size of private caches is to relax inclusion and build exclusive hierarchies. Thus, for the same total caching capacity, an exclusive cache hierarchy provides better cache access latency.
结果显示,增加私有缓存大小是为了放宽Inclusive Caches,,然后构建Exclusive Caches。因此,对于相同的总缓存容量,Exclusive Caches提供了更好的缓存访问延迟。
We observe that server workloads benefit tremendously from an exclusive hierarchy with large private caches. This is primarily because large private caches accommodate the large code workingsets of server workloads.
其实简而言之,就是Exclusive Caches+ large private caches让较大的应用收益更大。其中主要原因是大的L2 Cache可以容纳较大代码段。【一个疑问:在设计CPU架构时,什么时候使用Inclusive,还是使用Exclusive?与Mesh架构关系是什么?】
一个简单的实验证明
为了分析当前Cache中L2 cache miss与L3 cache miss到底谁占的比重更大,另外更深一层的想要判别代码和数据谁对性能的影响更大(对应FE和BE),设计了下面的对比实验:
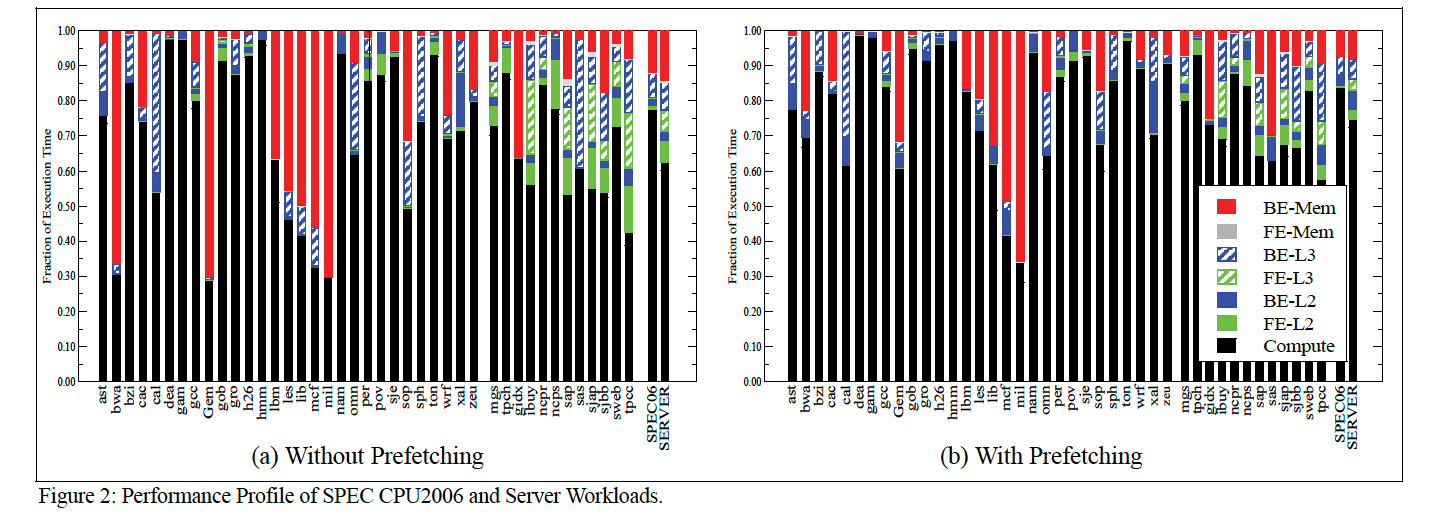
配置:L2 cache = 256K, LLC = 32M
一些场外信息:ast到zeu属于小工作集应用,mgs到tpcc属于大工作集应用,从上图的测试中可以看出:
- 在同一个条件下(关或者打开预取),mgs~tpcc相比ast~zeu,FE-L3和FE-2的数据明显突出;
- 打开预取后,FE-L3和FE-2的仍然突出,但是数据相对变少;
The figure shows that several workloads spend a significant fraction of total execution time stalled on shared LLC access latency. These stalls correspond to both code and data misses in the private L1 and L2 caches. For example, the figure shows that server workloads can spend 10-30% of total execution time waiting on shared LLC access latency (e.g. server workloads ibuy, sap, sjap, sjbb, sweb and tpcc)(主要看FE-L3). This implies that the workload working-set size is larger than the available L2 cache. Specifically, the large code working set size corresponds to high front-end stalls due to shared LLC access latency. Similarly, the large data working set sizes of both server and SPEC workloads contribute to the back-end stalls related to shared LLC access latency(自己和自己比). Furthermore, note that hardware prefetching does not completely hide the shared LLC access latency.
主要说明了:若干用例的有大量的可执行时间(大约占总时间的10-30%)是由于LLC导致的。主要原因是其工作集大小超过了L2 Cache大小;这里细分成大代码工作集(the large code working set)和大数据工作集(the large data working set):
- 大代码工作集:由于L2 cache miss导致的较大front-end stall(从mgs~tpcc);
- 大数据工作集:由于L2 cache miss导致的较大back-end stall;
所以,揉在一起,增大L2可以降低大代码工作集前端的延迟和大数据工作集后端的延迟。另外也说明了一点,硬件预取并不能完全解决LLC访问延迟(但是从上图BE-L3来看解决了大部分)。
通过上面这个数据,论文作者认为当前的访存瓶颈从内存转移到了LLC,主要是由于这些工作集都普遍大于L2 Cache。所以需要重新思考L2 cache设计。
关于L3最佳大小描述:
CPU2006的MPKI数据显示如果LLC在4MB的时候非常好,LLC在2.5MB之后MKPI提升10%性能只有1~3%的提升,2.5MB LLC cache是 CPU core 1/2 的芯片面积,因此若将LLC 由2.5MB升级到4MB,换算成CPU core的芯片面积是增长30%(1/2 * 1.5M/2.5M),但性能仅仅提升最多3%,这就是为什么基于CPU2006的benchmark条件下,intel将LLC设定为2~2.5MB的原因。
原文链接:https://plantegg.github.io/2021/07/19/CPU性能和CACHE
论文中会涉及两个术语:
- CLIP(Code Line Preservation):这篇论文提出的一种在L2保护Code类Cache Block的Cache策略;
- RRIP(Re-Reference Interval Prediction):早就存在的Cache策略,见参考中引用;
L2与LLC容量权衡?代码与数据孰轻孰重?
论文的目的是想证明L2 cache的容量比L3 cache重要,增大L2 cache大小可以让更多的数据和代码在L2命中,避免命中L3延迟较大的问题。但是增大L2 cache带来的性能提升得益于代码部分还是数据部分较多?为了分析这个问题,作者又设计了下面一个实验:
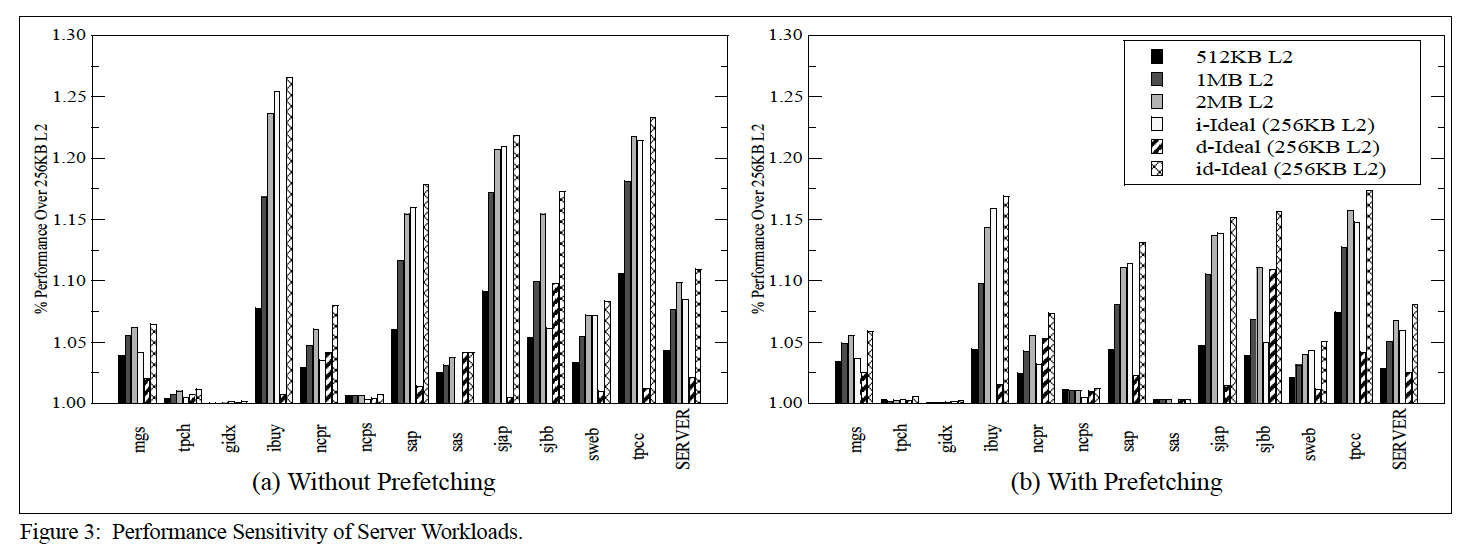
图中i-ideal、d-ideal和id-ideal含义:
(a) code requests always serviced at MLC hit latency (i.e. assume zero LLC hit latency) labeled as i-Ideal
(b) data requests always serviced at L2 hit latency (labeled as d-Ideal)
(c) both code and data requests serviced at L2 hit latency (labeled as id-Ideal).
上图导读:
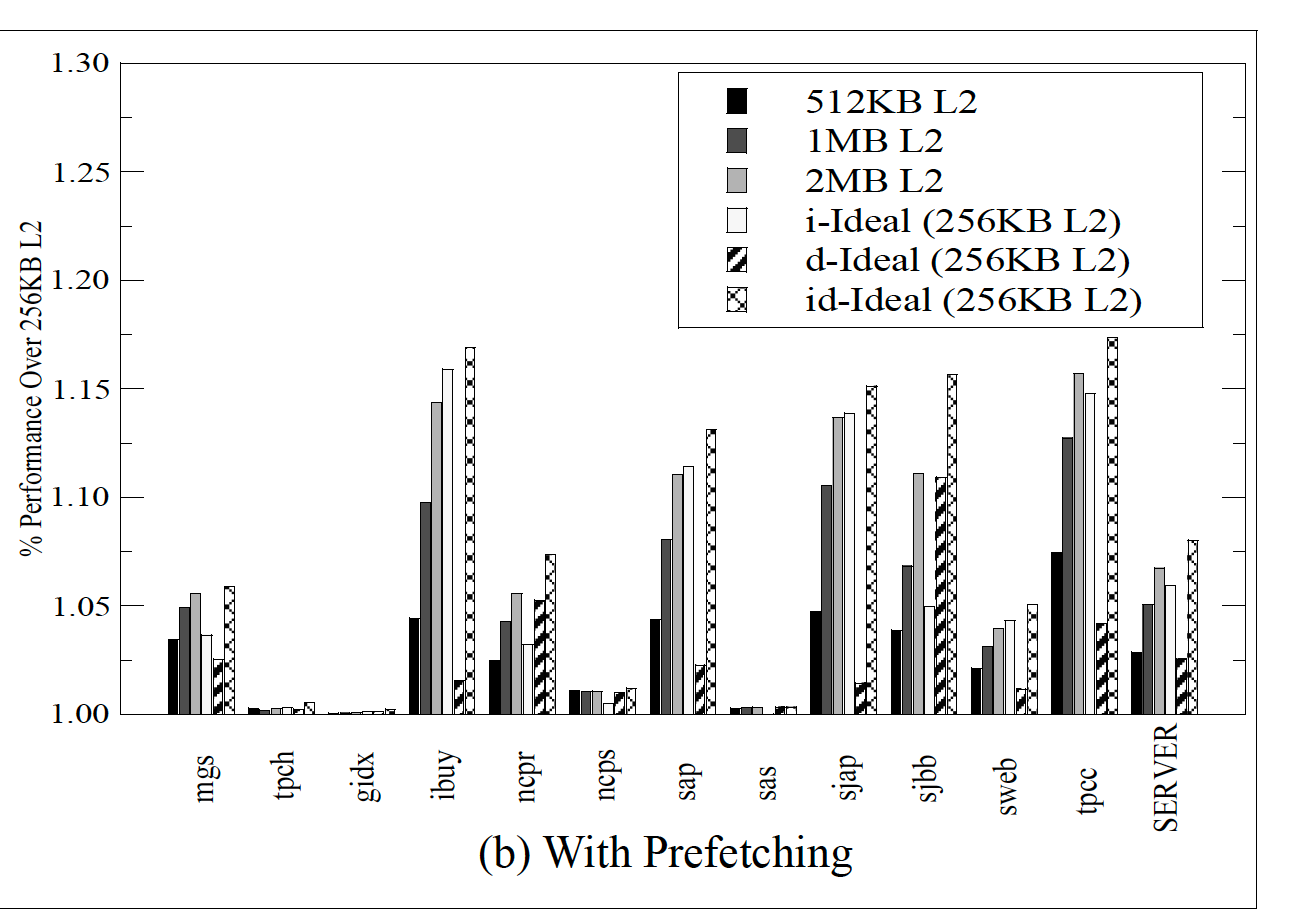
以256K L2作为base数据,分别仿真增大L2后:512K、1M、2M以及i-ideal、d-ideal和id-ideal的性能增长比值。
(1)首先,id-ideal的性能肯定比i-ideal和d-ideal好(对比最后三个,基本都是第三个性能最佳);
(2)i-ideal和d-ideal到底谁带来的性能最佳?将倒数二三和倒数一对比,基本是i-ideal与id-ideal最接近,但是ncpr、sjbb意外,因为代码部分太小;
(3)1MB L2性能与i-ideal基本相似;
实验结论:在L2中代码比数据对性能影响更大,同时增大L2容量到1MB基本可以达到理想的icache水平,2MB L2完全没有必要。
增大L2 cache后可能存在几个影响,论文中列举了以下几个:
- Longer L2 Cache Latency:Our analysis with both methods showed that increasing the L2 cache size causes a cache latency increase of one and two clock cycles for a 1MB and 2MB L2 cache respectively, while a 512KB L2 cache has no access latency impact. Our studies showed that performance impact due to increasing the L2 cache latency is minimal (less than 1% on average).(简而言之,影响不大,在1%以内)
- On-Die Area Limitations for Cache Space(如果是Inclusive cache,需要保证L2:LLC ratio(如果LLC小于L2的4倍或者8倍的时候,就会出现空间浪费的问题),另外同时增大L2和LLC不可取,只能采用Exclusive cache);
- Relaxing Inclusion Requirements
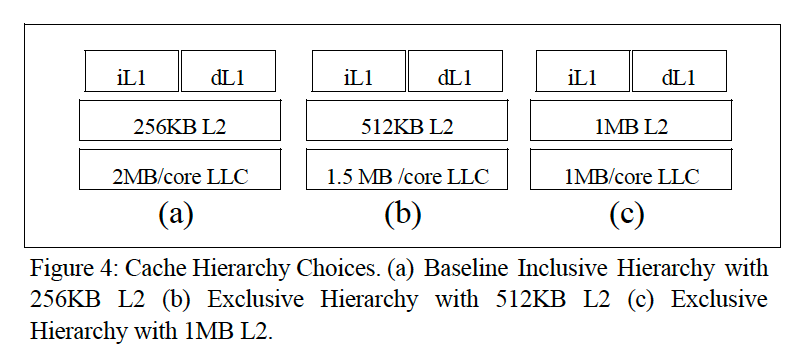
上面三种情况基本覆盖了我们当前使用的intel和arm机器类型。
- Tradeoffs of Relaxing Inclusion
结论就是使用Exclusive cache可以带来给云应用带来潜在的性能提升。
关于Exclusive LLC策略
Exclusive cache与Inclusive cache在缓存逻辑上有些变化,例如Exclusive cache中,L2直接从内存中读取数据,该数据并不会缓存到LLC中(下图过程1),而在L2中被驱逐时,那些会被其他核共享的数据才会被转移到LLC(过程3)。剩下的过程2指写回过程。
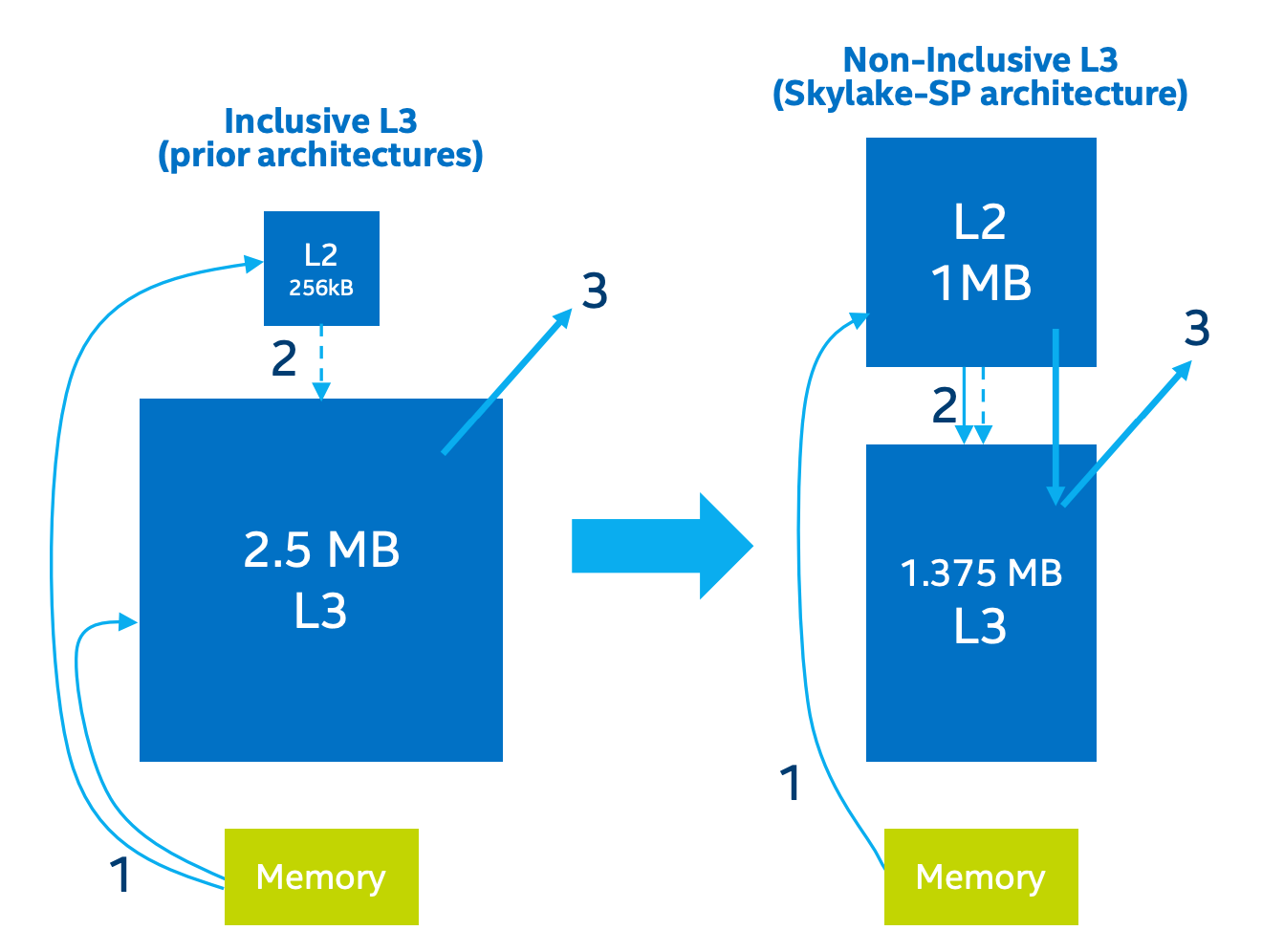
这点论文以外的内容加到这里用来理解下面出现的两个Cache策略为什么在L2要考虑Cache Block来自Memory还是LLC。详细参考【2】。
在从Inclusive LLC到Exclusive LLC切换过程中,原本的Cache策略也需要做一些调整。
SFL bit
在Inclusive LLC中,LLC保存有所有的引用信息。
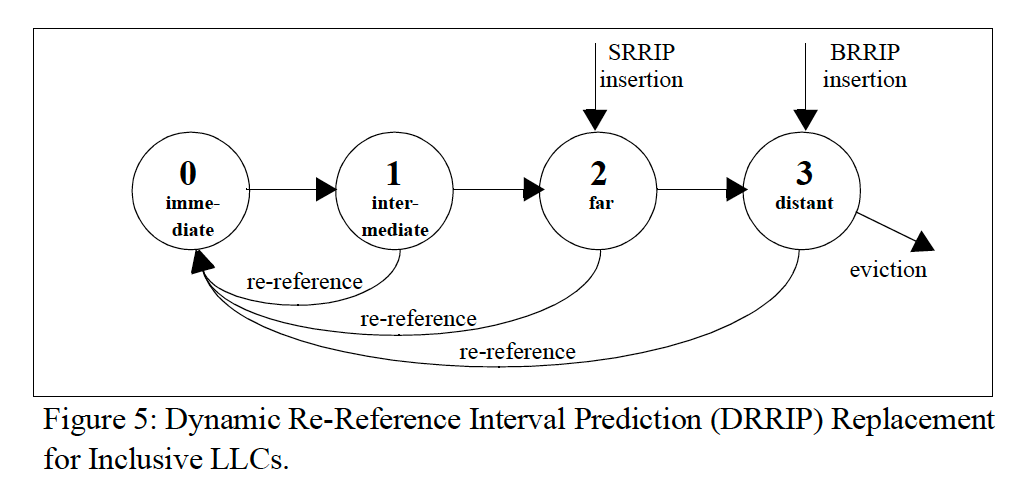
用2 bits表示四种状态。
(1)总是驱逐distant cache line,如果没有,所有cache line状态加1;
(2)插入好几个line时,统一初始化为far,如果这几个line局部性较好,会立即变为immediate状态;
但是在Exclusive cache中,缺少该line时来自LLC还是Memory的信息。所以无法决策当一个line从L2驱逐的时候,状态应该是什么?或该驱逐哪一个LLC line?在论文里边在L2中引入一个Serviced From LLC (SFL) bit记录L2 line来自LLC还是Memory。
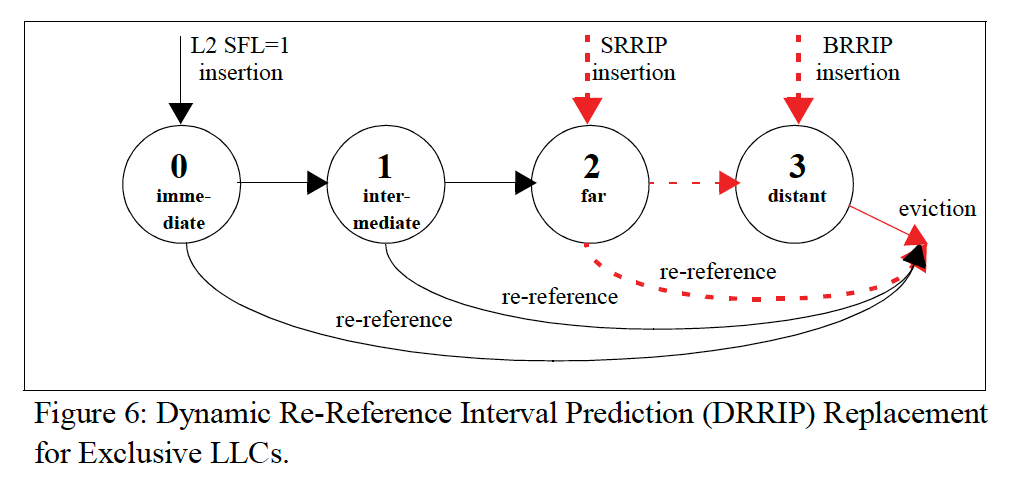
(1)如果从L2驱逐时,SFL=0(来自memory的数据),在LLC就为far;
(2)如果从L2驱逐时,SFL=1(原本来自LLC的数据),在LLC就为immediate;
这里随便加一个提示:注意上面两张图中re-reference箭头的方向存在差异,比如在Exclusive Cache中,re-refernece指向了eviction,因为对于Exclusive Cache,一旦被L2 Cache需要时,就需要从LLC中驱逐掉。
Code Line Preservation (CLIP)
在L2中保护代码。
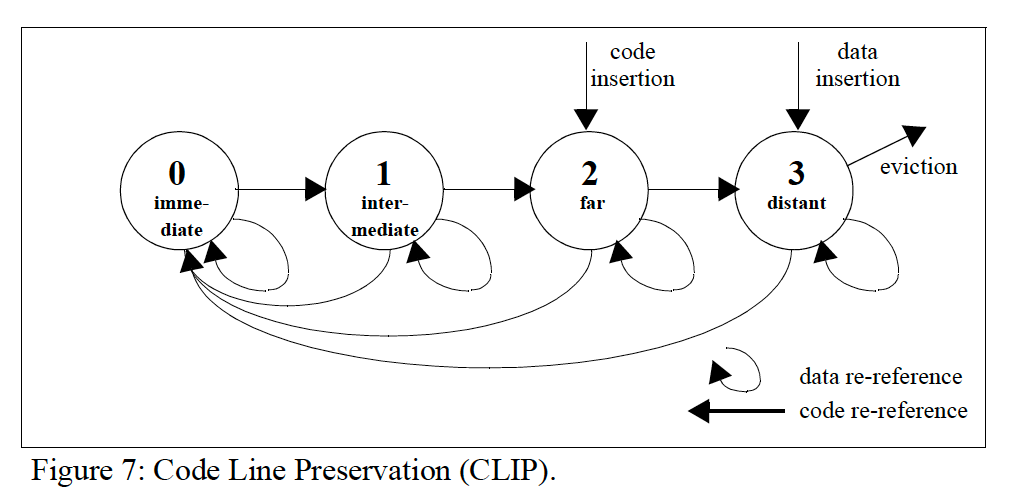
对于代码而言,设置RRPV=2(正常的DRRIP),而数据仅设为RRPV=3,简而言之,就是让数据段更容易被L2驱逐。(代码部分设RRPV=1,数据部分设RRPV=2的效果如何?)。
如此又引入新的问题:While CLIP enables preservation of code lines in the L2 cache, blindly following CLIP can degrade performance when the instruction working set does not contend for the L2 cache (e.g. SPEC workloads).(对于本身不存在L2竞争的应用,CLIP存在负优化。)
解决办法:CLIP samples a few sets of the cache (32 in our study)(对一些Cache Sets的代码和数据访问进行采样) to always follow the baseline RRIP replacement policy. The sampled sets track the number of code and data misses in the L2 cache. Furthermore, CLIP also tracks the number of code and data accesses to the L2 cache. If the ratio of code accesses and misses to total accesses and misses exceeds a given threshold, θ, (一个阈值,超过该阈值,说明代码部分命中率较低)CLIP dynamically modifies the re-reference interval for data requests. Specifically, if the ratio of L2 code accesses and misses exceeds θ (25% in our studies) the L2 cache follows CLIP for the non-sampled sets(当发现代码命中率较低,则对非采样的Cache Set采用CLIP策略). If not, CLIP follows the baseline RRIP policy.
实验部分
CMP仿真
配置:
配置项 | 值 |
基本 | 16 cores |
baseline | 256KB L2 cache and a 32MB inclusive LLC |
测试1 | 512KB L2 cache and a 24MB exclusive LLC |
测试2 | 1MB L2 cache and a 16MB exclusive LLC |
CLIP的单核影响:
改变L2 cache与256KB L2基线对比:
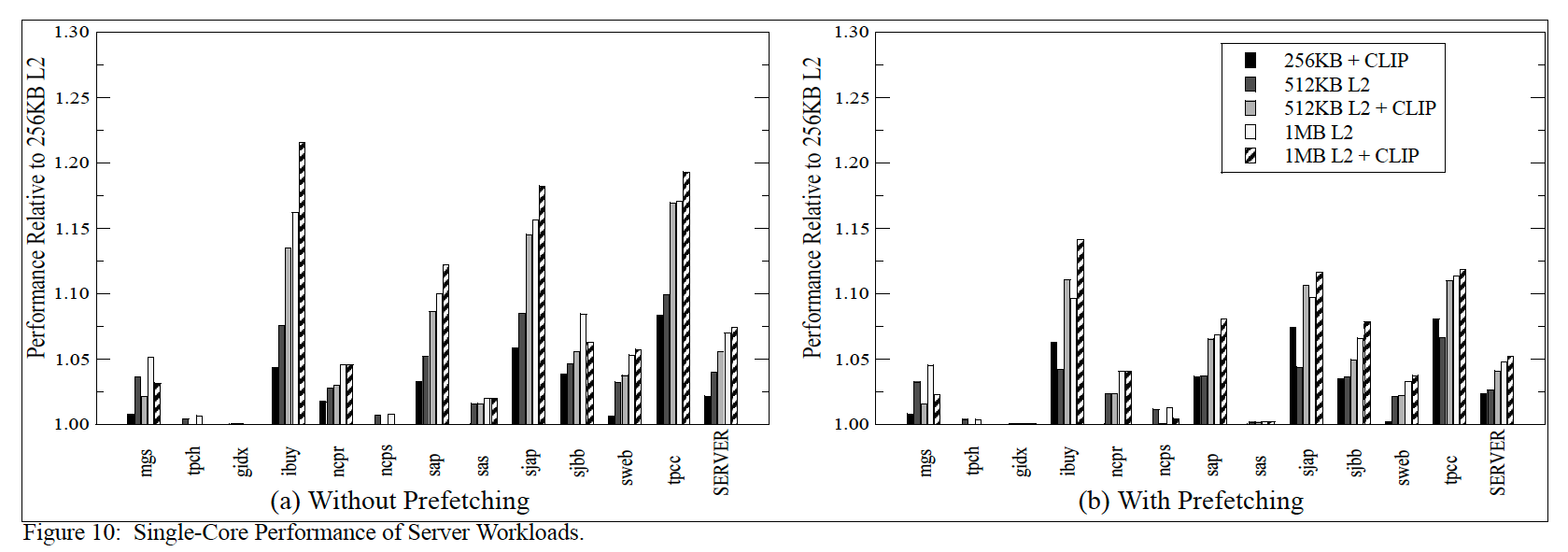
The figure shows that simply applying CLIP to the baseline 256KB L2 cache improves performance of five of the 12 server workloads by 5-10%(CLIP带来的性能提升) both in the presence and absence of prefetching. The benefits of CLIP reduce in the presence of prefetching because useful code prefetches hide latency. Where CLIP helps, we see that CLIP provides nearly the same performance as doubling the L2 cache size(观察512KB L2 + CLIP VS 1MB L2).
MPKI指标对比:
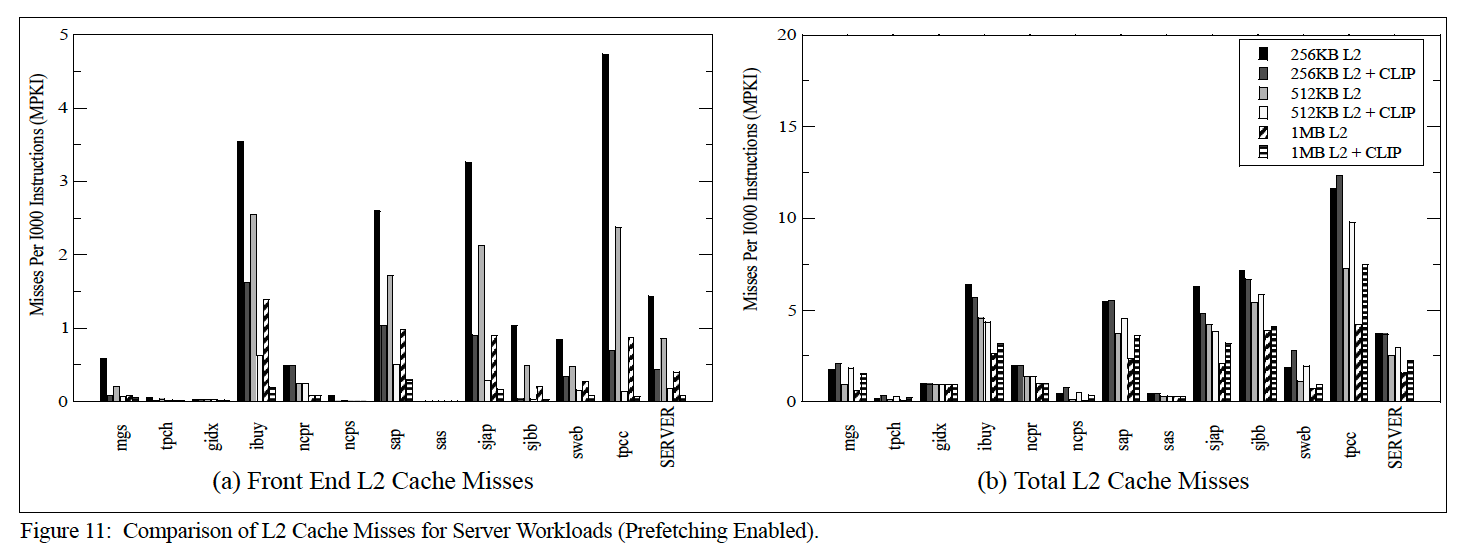
As expected, the figure shows that the server workloads with the largest front-end MPKI benefit the most from CLIP and increasing L2 cache sizes(其实就是代码部分较大的那些用例). From Figure 11a, CLIP performance can be correlated directly to the large reductions in L2 front-end MPKI. Note that while CLIP helps reduce front-end cache misses, it does so at the expense of increasing L2 cache misses (see Figure 11b)(例如对比512KB L2和512KB L2+CLIP,mgs、sap、sjbb、sweb、tpcc等用例中有CLIP的MPKI指标反而增加). This is to be expected because CLIP prioritizes front-end code requests over data requests. Note that even though CLIP increases total L2 cache misses, overall system performance improves significantly. This clearly illustrates the criticality of code requests over data requests and the importance of avoiding hiccups in the processor front-end.
CLIP的多核影响:
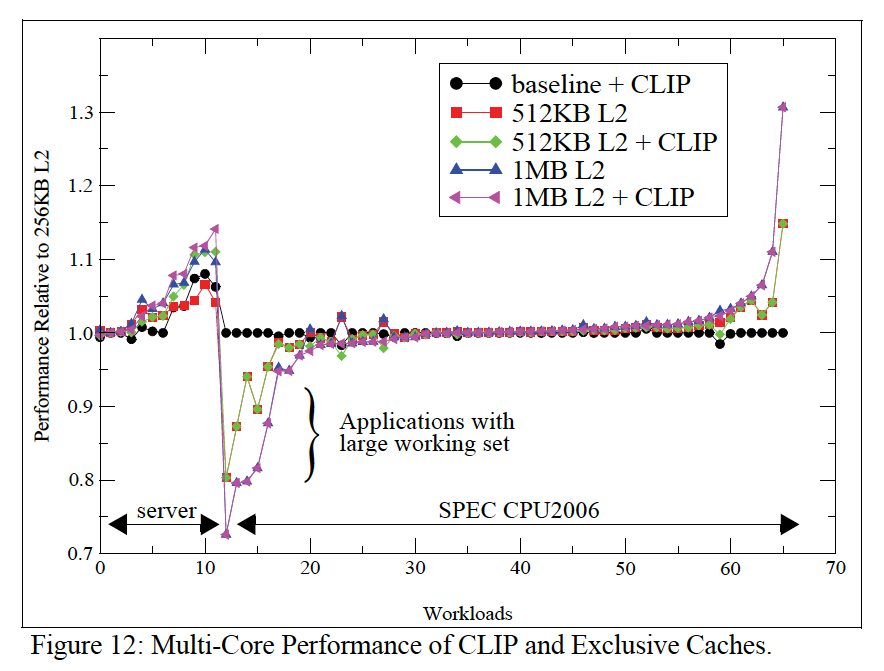
The figure shows that increasing the L2 cache and reducing the LLC has both positive and negative outliers for SPEC CPU2006 workloads. The positive outliers are for workloads that benefit from improved L2 cache access latency when the working set fits in the L2 cache. The negative outliers are for those workloads whose working set fits in the baseline large shared LLC but no longer fit in the exclusive hierarchy with smaller shared LLC. The outliers can be as significant as 30% performance degradation for a single-core run of libquantum. This is to be expected as libquantum has a 32MB working-set that fit nicely in the baseline inclusive hierarchy. On the other hand, calculix observes a 30% performance improvement because its working set was larger than the baseline 256KB L2 cache but fits nicely into a 1MB L2 cache. The bimodal performance behavior of SPEC CPU2006 workloads provides no clear indication on whether or not to increase the L2 cache size. However, server workloads clearly show the need for a larger L2 cache. Thus, this provides avenue for academic research work on a general solution that would be applicable to both workload categories.
上图中出现双峰(纵坐标0~20区域)解读:
- 对于server workload,增加L2 cache,同时减小LLC容量是正向的优化,因为大多server workload更接近1MB L2 cache;
- 对于SPEC CPU2006,大多用例偏好较大的LLC;
cache层次结构性能
In a multi-core system, instruction working set duplication in private caches can reduce the effective caching capacity of an exclusive cache hierarchy (relative to the baseline inclusive cache hierarchy).
Assuming a shared code(指多线程情况?) working set of 1MB, an exclusive hierarchy with 1MB private L2 caches and 16MB LLC devotes only 15MB of the total 32MB (代码占17MB,数据仅能使用15M?)cache hierarchy capacity for the data working set. The baseline inclusive hierarchy on the other hand devotes 31MB of cache hierarchy capacity for the data working set and 1MB for the instruction working-set (preserved in the LLC)5. This reduction in effective caching capacity in the hierarchy for the data working can increase data traffic to memory. In fact, we see that server workloads such as mgs, ibuy, sap, sjap, sjbb, sweb, and tpcc observe a 10-20% increase in memory traffic (data not shown due to space constraints). This excess in memory traffic does not degrade memory performance since the processor front-end enables the back-end to exploit memory-level parallelism without too many front-end stalls.
到这里,这篇论文基本结束。简而言之,这篇论文就讲了这样一个故事:CPU片内互联结构往Mesh转移的大背景下,考虑内存墙有往LLC转移的趋势,降低LLC惩罚就显的重要。
为什么需要采用Exclusive Cache?
回到“Intel平台Haswell到Skylake-SP一个比较重要的变化就是将原来的Inclusive Cache改换为Exclusive Cache,这种调整是出于什么考虑?”,我总结了一下intel这样做的逻辑链条可能是这样:
Skylake单片要做22~28 cores -> 28 cores下ring互联coherence延迟太大,尤其是存在Node间LLC Snooping时NUMA访存性能极差 -> 改成mesh互联 + directory-based LLC -> 既然做成mesh了,core间的带宽大了一个数量级,L2 miss后轻轻松松的直接去其他LLC Slice获取或者主存读取,那么没必要在L2 cache和LLC cache维持两份拷贝了 -> L2增大,L2/LLC比例增大,也不得不选择Exclusive LLC -> 同时顺水推舟,增大L2容量可以带来服务器端benchmark的性能收益和减少LLC miss惩罚(前面论文的故事)
其他可能性待补充。
伴读:Ring Bus VS Mesh
首先还是从Mesh基本内容说起。
为什么说Mesh是2D array of half-rings?

Mesh网络的路由算法较简单,例如最开始按列(垂直)路由到目标节点的行(水平),然后路由到目标节点。简而言之,就是“先列后行”。比如最开始一个包从CHA或IO设备出发,通过各Mesh Stop(CMS)最终到达。(当packet返回时,路径与原路径不一定相同,因为“先列后行”).
下面就以Broadwell和Skylake-SP为例,大致看看Ring Bus和Mesh差异:
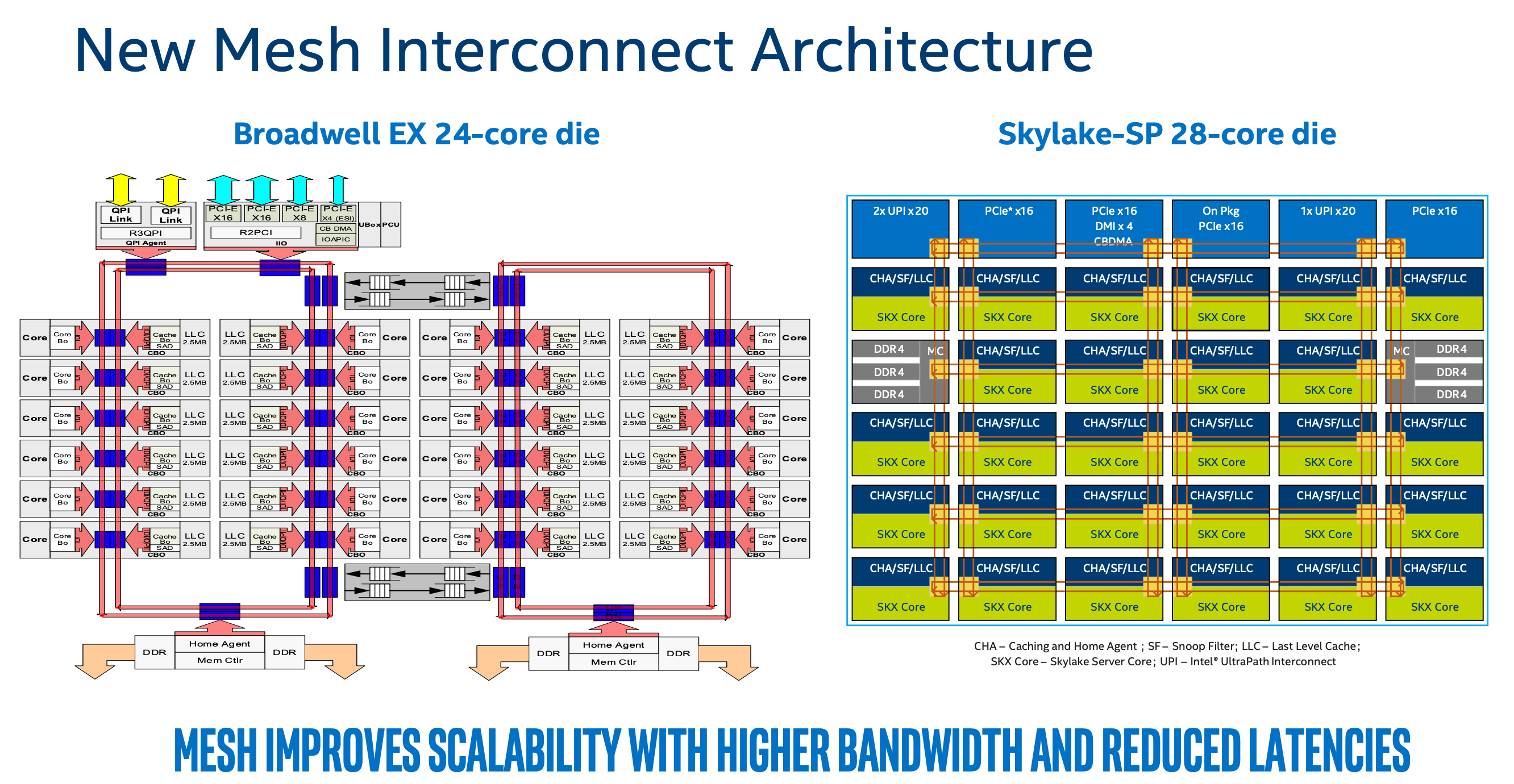
对比这两种架构,看上去Mesh最明显的优势就是每个核到两个node IMC的平均跳数(跨node访问的跳数也不会增加太多),而在Ring Bus中最坏情况是左上角的核跨node访问,大约要绕过半个Ring到另一个IMC。
关于Ring Bus:Ring Bus的工作频率一般与CPU Core相同,并由四个 Sub-Ring Bus 组成处理不同类型的事务(Transaction),分别是 Data Ring,Request Ring,Acknowledge Ring 和 Snoop Ring。这些 Sub-Ring Bus 协调工作,共同完成 Ring Bus 上的各类总线交互,如 Request、Data、Snoop和Response。采用 4 个 Sub-Ring Bus 可以最大程度使不同种类的 Transaction 并发执行。
关于Mesh Bus:在Intel CPU中,按Mesh大小,分为:
- Low Core Count (LCC):10-core
- High Core Count (HCC):18-core
- Extreme Core Count (XCC):28-core
以上图中Skylake-SP 28 cores为例,其Mesh大小为6x6,其中第一行6个主要是UPI、PCI等IO设备,另外第三行有两个IMC,因此留给核的位置就只剩下28=36-6-2。另外图中还剩下SF(Snoop Filter)未解释。顾名思义,Snoop Filter看上去是一种过滤Snoop事务的模块,在基于总线监听机制的高速缓存一致性协议中,某个核修改了某Cache Block数据(例如刷新或失效操作),此更改必须广播到所有缓存有该Cache Block的Cache中,保证缓存一致性。对于Inclusive LLC,包括了L1和L2的所有数据,是一个天然的Snoop Filter。而在Exclusive LLC中,就需要单独的Snoop Filter保存L1和L2 Cache数据,防止不必要的监听进入到L2 Cache,引起不必要的功耗和带宽浪费。因此从功能上可以看出Snoop Filter的大小至少等于L2 Cache大小。这节末尾附上的《几句话说清楚37:Skylake Non-inclusive缓存和Snoop Filter的关系》对Snoop Filter总结很直观,可以参考(我理解SF的作用就是把原来瞎广播变成有点到点的广播,跟踪cache line属于哪些core的,就是directory-based cache中目录的作用)。
Distributed CHA
与Ring Bus相比,在Mesh中采用Distributed CHA似乎是很自然的事情,毕竟不太可能在两个IMC旁边集中放两个CHA。关于CHA的位置和优势从下面这张PPT中可以获取到。
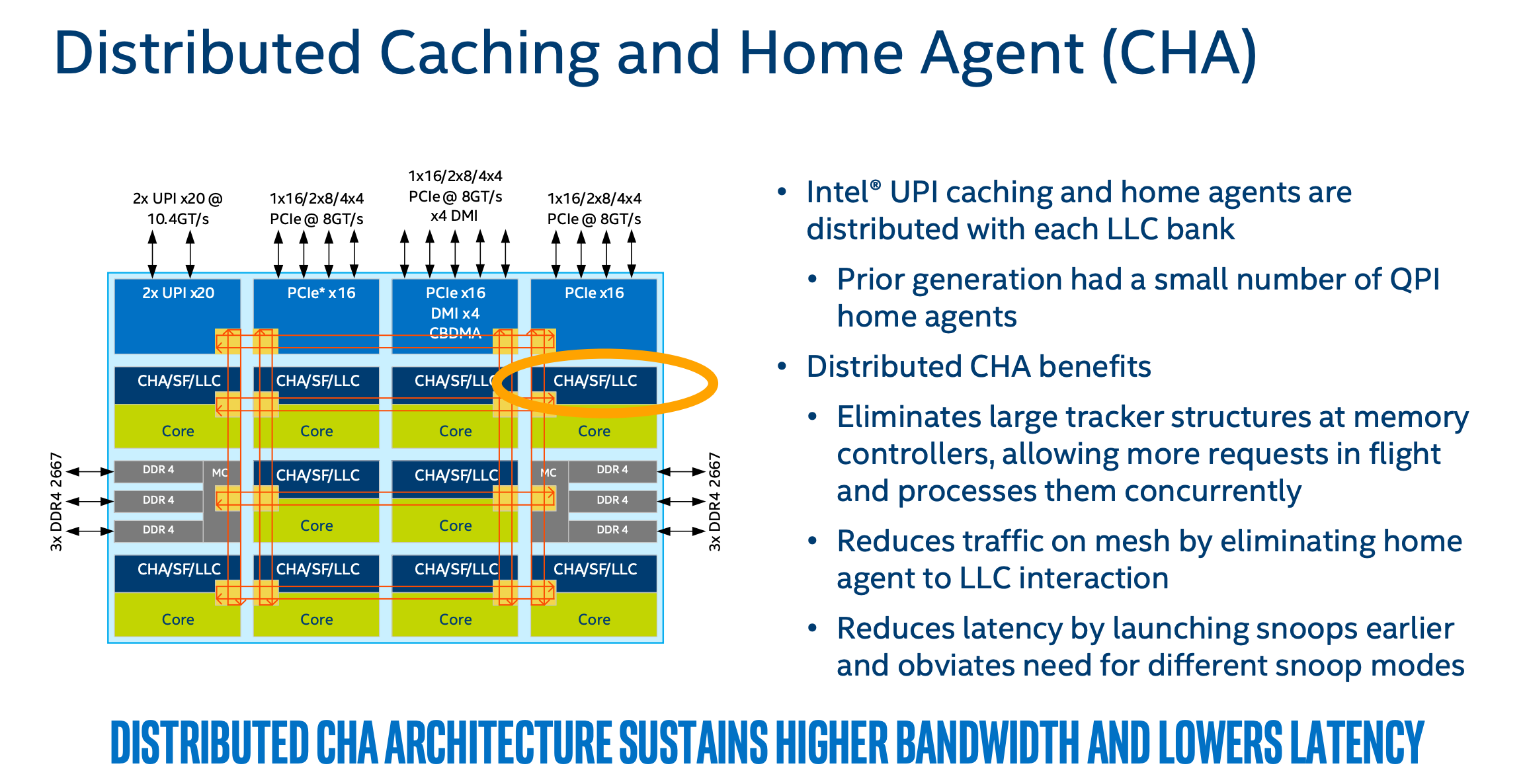
尽管列举了这么些“显而易见”的优势,但是还是无法完全弥补Mesh架构本身的缺陷,比如L2 Cache和LLC延迟的增加(L2 Cache延迟增加主要是由于容量的翻倍,LLC延迟增加就更显而易见了)。这里有一份关于各层Cache延迟对比,如下:

所以,容纳更多核和Cache延迟在这里应该又是一次tradeoff吧。
一些材料来自:intel-xeon-scalable-architecture-deep-dive_1.pdf
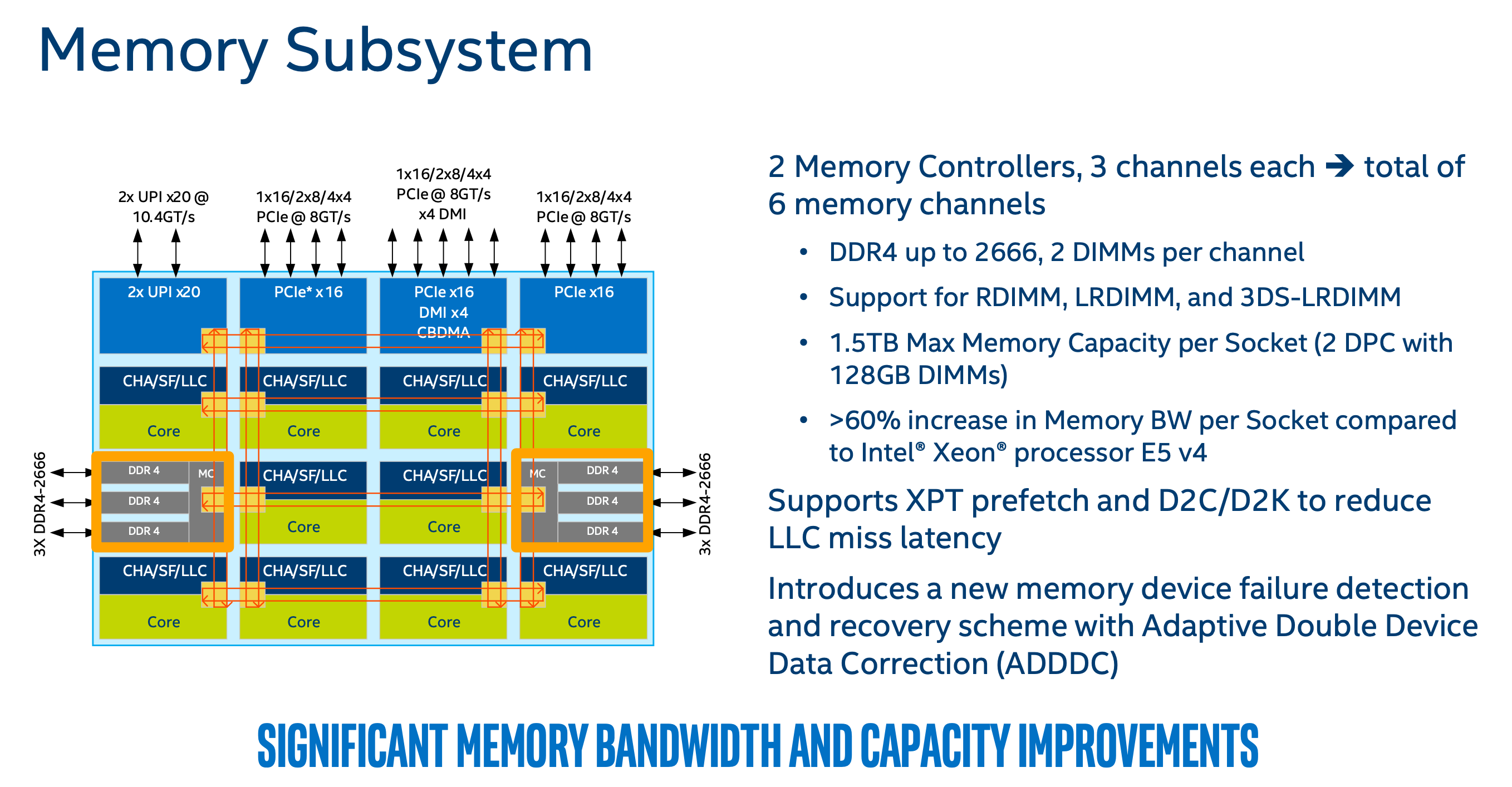
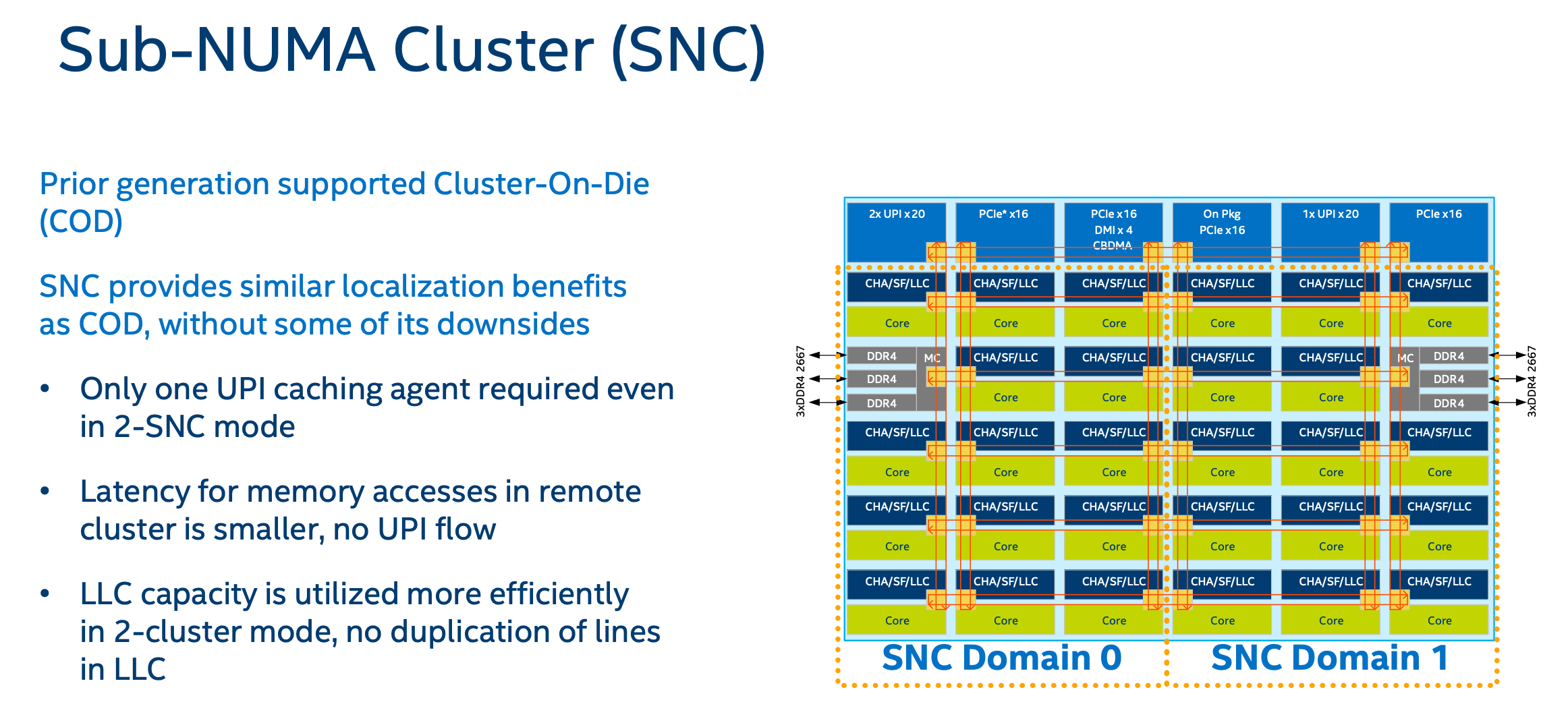
Memory Subsystem
这里先塞几张图。除了Mesh升级了配置,带宽各方面碾压外,剩下的SNC并没有感知,大多数业务NUMA可能都没有打开,更别说SNC。

最后带上与本文相关的文章:
破茧化蝶,从Ring Bus到Mesh网络,CPU片内总线的进化之路
几句话说清楚37:Skylake Non-inclusive缓存和Snoop Filter的关系
处理器中的存储问题(五):以Skylake为例谈cache的包含策略
Understanding Skylake’s CHA - kongchung - 博客园
Q&A
为什么不直接增大L2,偏偏要另外加上个L3?
L3对SPEC CPU基准还是有效的。
参考
【1】RRIP、BRRIP、SRRIP是什么?
https://zhuanlan.zhihu.com/p/489828595
【2】片内互联演变与cache关系:
https://aijishu.com/a/1060000000198141
【3】The New Intel Mesh Interconnect Architecture and Platform Implications
【4】另外两篇同类型论文
- A CASE FOR SPECIALIZED PROCESSORS FOR SCALE-OUT WORKLOADS: "Data working sets of scale-out workloads considerably exceed the capacity of on-chip caches. Processor real estate and power are misspent on large last-level caches that do not contribute to improved scale-out workload performance"
- Scale-Out Processors: “we observe that LLC capacities of 2-8MB are sufficient to capture the instruction footprint and secondary working set. Beyond this range, larger cache configurations provide limited benefit because the enormous data working sets of the applications exhibit little reuse in the LLC."
附录
几颗CPU的核心参数如下表:
CPU型号 | Hygon 7280 | Hygon 5280 | AMD EPYC 7H12 | Intel 8163 (Skylake-X) | 鲲鹏920 | 飞腾2500 | Ampere Altra |
物理核数 | 32 | 16 | 64 | 24 | 64 | 64 | 64 |
超线程 | 2 | 2 | 2 | 2 | 无 | 无 | 无 |
L1d/L1i | 32K/64K | 32K/64K | 32K | 32K | 64K | 32K | 64KB/64KB |
L2 | 512K | 512K | 512K | 1024K | 512K | 2048K(4c) | 1024K |
L3/core | 8M/4 | 8M/4 | 16M | 32M/24 | 64M/64 | 64M/64? | 32MB/64 |
片内互联 | FULL MESH | FULL MESH | Mesh | RingBus | Mesh | Mesh |
注意L3是每core展示,非每thread。
所以从L2 Cache容量大小基本可以判断属于Ring Bus还是Mesh。