内存怪谭
写在前面
本系列主要用于记录Linux内核内存BUG相关的故事,以及一些内存奇闻轶事。
shmem - sleep in atomic context
这个BUG在我们龙蜥cloud-kernel的4.19中用stress-ng压测复现。通常情况下,这个BUG对系统稳定性影响并不是很大,仅仅在CONFIG_PREEMPT_COUNT打开的情况下才会,而这个config属于debug类型,一般情况下不会打开。接下来,就分享一下这个怪异的BUG是如何在CONFIG_PREEMPT_COUNT打开的情况下触发的。
首先
#ifdef CONFIG_PREEMPT_COUNT
#define preempt_disable() \
do { \
>-------preempt_count_inc(); \
>-------barrier(); \
} while (0)
#define preempt_enable() \
do { \
>-------barrier(); \
>-------preempt_count_dec(); \
} while (0)
#define preempt_count_add(val)>-__preempt_count_add(val)
#define preempt_count_sub(val)>-__preempt_count_sub(val)
#define preempt_count_inc() preempt_count_add(1)
#define preempt_count_dec() preempt_count_sub(1)
static __always_inline void __preempt_count_add(int val)
{
>-------raw_cpu_add_4(__preempt_count, val);
}
static __always_inline void __preempt_count_sub(int val)
{
>-------raw_cpu_add_4(__preempt_count, -val);
}
#else /* !CONFIG_PREEMPT_COUNT */
#define preempt_disable() barrier()
#define preempt_enable() barrier()
#endif下面是这个BUG最坏情况下宕机,打印的信息:
BUG: sleeping function called from invalid context at mm/vmscan.c:2880
BUG: sleeping function called from invalid context at mm/shmem.c:2801
Kernel panic - not syncing: Aiee, killing interrupt handler!
[24505.648944] Kernel panic - not syncing: Aiee, killing interrupt handler!
[24505.648947] CPU: 43 PID: 9304 Comm: stress-ng-shm-s ... 4.19.91-27_rc2.al7.x86_64.debug
[24505.648948] Hardware name: Alibaba Alibaba Cloud ECS/Alibaba Cloud ECS
[24505.648949] Call Trace:
[24505.648957] dump_stack+0xaf/0xfb
[24505.648963] panic+0x128/0x2a1
[24505.648969] ? netlink_broadcast_filtered+0x167/0x540
[24505.648973] do_exit+0xbec/0xf00
[24505.648977] do_group_exit+0x46/0xc0
[24505.648981] get_signal+0x1b6/0xc40
[24505.648989] do_signal+0x36/0x620
[24505.648992] ? force_sig_info_fault+0xbc/0x120
[24505.649002] exit_to_usermode_loop+0x63/0xd1
[24505.649005] ? page_fault+0x8/0x30
[24505.649007] prepare_exit_to_usermode+0xea/0xf0
[24505.649009] retint_user+0x8/0x18
[24505.649040] RIP: 0033:0x40bf05踢掉一些干扰信息后,简单梳理一下上面这些系统宕机前的“遗言”:
- BUG: sleeping function called from invalid context at mm/vmscan.c:2880
- BUG: sleeping function called from invalid context at mm/shmem.c:2801
- retint_user() -> ... -> get_signal() -> do_exit() -> panic()
在彻底解决这个BUG前,我们没法站在上帝视角来判断这些信息关系,比如可能会猜测上面三条信息有可能不相干,或者前两个并非导致系统宕机,而第三个才是导致系统宕机的真凶。
先易后难的原则,我们首先找到“BUG: sleeping function called from invalid context”的出处。如下:
void ___might_sleep(const char *file, int line, int preempt_offset)
{
>-------...
>-------if ((preempt_count_equals(preempt_offset) && !irqs_disabled() &&
>------- !is_idle_task(current)) ||
>------- system_state == SYSTEM_BOOTING || system_state > SYSTEM_RUNNING ||
>------- oops_in_progress)
>------->-------return;
>-------...
>-------printk(KERN_ERR
>------->-------"BUG: sleeping function called from invalid context at %s:%d\n",
>------->------->-------file, line);
>-------printk(KERN_ERR
>------->-------"in_atomic(): %d, irqs_disabled(): %d, pid: %d, name: %s\n",
>------->------->-------in_atomic(), irqs_disabled(),
>------->------->-------current->pid, current->comm);
>-------...
>-------dump_stack();
}对___might_sleep()调用链上的函数走读,我们了解到诸如cond_resched()的地方最终都会调用到___might_sleep()。这条信息贴出权当所有读者不知道,且后续会用到该条信息。
所以,接下来,需要走读一下“mm/vmscan.c:2880”、“mm/shmem.c:2801”处的代码,这两处的警告信息打印原因相同,选择以“mm/vmscan.c:2880”的代码简单描述一下:
do_fault()
--> shmem_getpage_gfp()
--> shmem_add_to_page_cache()
--> mem_cgroup_uncharge_swap()
--> shmem_alloc_page()
--> try_charge()
--> try_to_free_pages()
--> try_to_free_mem_cgroup_pages()
--> shrink_node()
--> shrink_node_memcg()
--> ___might_sleep()注:省略部分函数
简单说明一下上面的函数调用链的场景:try_charge()之前可以简单的认为就是shmem内存访问的路径,往pagecache中申请和添加页,在try_charge()之后的函数中,当该进程占用的内存已经达到所属memcg内存上限时,会触发try_to_free_pages()回收内存的路径。最终走到shrink_node_memcg(),即“mm/vmscan.c:2880”所属函数。继续,因为在shmem_getpage_gfp()中调用shmem_add_to_page_cache()前,会调用radix_tree_maybe_preload_order(),从而调用preempt_disable(),这也表明shmem_add_to_page_cache()在一个原子上下文中,不应该调用cond_resched()。
因此,综合以上两条信息,确定了“BUG: sleeping function called from invalid context”打印的原因。接下里,还需要解释为什么会宕机?
对上面的panic栈回收稍稍整理,继续观察:
retint_user()
--> prepare_exit_to_usermode()
--> exit_to_usermode_loop()
--> force_sig_info_fault()
--> do_signal()
--> do_group_exit()
--> do_exit()
--> panic()然后再贴一段do_exit():
void __noreturn do_exit(long code)
{
>-------...
>-------if (unlikely(in_interrupt()))
>------->-------panic("Aiee, killing interrupt handler!");
>-------if (unlikely(!tsk->pid))
>------->-------panic("Attempted to kill the idle task!");
>-------...
}in_interrupt()的返回值与preempt_disable()有关。
综合以上信息,大胆的猜测:假如一个正在使用shmem的进程,其内存使用达到了所属memcg的上限,导致下一次访问新的shmem内存时,走到了shrink_node_memcg()中由于cond_reched()开始睡眠,附带一次preempt_disable()调用。在达到memcg上限的情况下,也极有可能触发OOM,导致对该进程执行kill(即发送kill信号),直接kill的路径会走do_exit()路径,因此触发了panic("Aiee, killing interrupt handler!")。
注:OOM在最开始发生的时候,会尝试回收内存,但一旦回收也无法满足进程的需要,就会开始kill掉优先级比较低的进程,若此时满核都触发OOM,就会造成系统所有用户进程被kill掉的可能,stress-ng或ltp内存压测很常见。
当然,为了验证上面的猜测,我们完全可以写一个测试用例证明:
使用shmem内存的shmem.c程序:
#include <stdio.h>
#include <sys/mman.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdlib.h>
#include <unistd.h>
#define MAP_SIZE (2024 * 1024 * 1024)
int main(int argc, char *argv[])
{
int fd;
void* result;
unsigned long i;
unsigned long *mem;
fd = shm_open("shm1", O_RDWR|O_CREAT, 0644);
if(fd < 0){
printf("shm_open failed\n");
exit(1);
}
if (ftruncate(fd, MAP_SIZE) < 0){
printf("ftruncate failed\n");
exit(1);
}
result = mmap(NULL, MAP_SIZE, PROT_READ|PROT_WRITE, MAP_SHARED, fd, 0);
if(result == MAP_FAILED){
printf("mapped failed\n");
exit(1);
}
mem = (unsigned long *)result;
for (i = 0; i < MAP_SIZE / 8 - 1; i++)
mem[i] = 1;
while(1);
}测试脚本:shmem_setup.sh
#!/usr/bin/env bash
echo "7 4 1 7" > /proc/sys/kernel/printk
gcc shmem.c -o shmem.out -lrt
mkdir /sys/fs/cgroup/memory/test
cgexec -g memory:test ./shmem.out
echo 500M > /sys/fs/cgroup/memory/test/memory.limit_in_bytes
echo 500M > /sys/fs/cgroup/memory/test/memory.memsw.limit_in_bytes另外,为了制造更大的压力,可并行执行多个shmem.out进程复现。
最后小结一下,这个问题是一个非常普遍的操作系统面试题,比如为什么不能在中断上下文睡眠?或者中断上下文睡眠会发生什么?这个BUG是关于这个问题的典型代表,站在Linux内核实现角度,上面的BUG就是在原子上下文睡眠最坏的后果之一。
链接:
【1】https://bugzilla.openanolis.cn/show_bug.cgi?id=2743
【2】https://bugzilla.openanolis.cn/show_bug.cgi?id=3294
莫名其妙的page fault
spawn是unixbench中的一项测试,其代码逻辑很简单,就是父进程单纯的不断调用fork()生产子进程,测试的是一定时间内fork的次数。看上去测试的是系统fork进程的吞吐量。
还在21年的时候,我们就碰到了这个问题,当时还无关紧要,无脑的认为是一些栈数据因为COW产生的大量缺页异常。最近性能的同学测试unixbench再次抛出了这个问题,因此不得不一探究竟。
unixbench/spawn.c写的有点花里胡哨,在这里贴一个简单版本的spawn.c:
#define _GNU_SOURCE
/*
* Process creation
*/
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/wait.h>
#include <sys/syscall.h>
unsigned long iter;
int main(int argc, char *argv[])
{
pid_t slave;
int status;
iter = 0;
while (1) {
if ((slave = fork()) == 0) {
// if ((slave = syscall(SYS_fork)) == 0) {
/* slave */
/* exit right away */
exit(0);
// syscall(SYS_exit, 0);
} else if (slave < 0) {
/* woops ... */
fprintf(stderr,"Fork failed at iteration %lu\n", iter);
exit(2);
} else {
/* master */
wait(&status);
}
if (status != 0) {
fprintf(stderr,"Bad wait status: 0x%x\n", status);
exit(2);
}
iter++;
}
}下面是我们统计10秒spawn.out的发生缺页异常,分别包括或不包括子进程的缺页计数:
# perf stat -e faults -p 78526 -- sleep 10
Performance counter stats for process id '78526':
1,821,638 faults
10.001264575 seconds time elapsed
# perf stat -e faults -i -p 78526 -- sleep 10
Performance counter stats for process id '78526':
216,014 faults
10.001247136 seconds time elapsed进程2007872为spawn.out,其中-i表示忽略子进程计数
按照上面的数据大致统计了一下,在10秒内,父进程/子进程 缺页中断比例为:1/7
从spawn.c源码中,子进程并没有访问任何的内存,应该不会触发如此多的缺页异常。该数据有些反常,所以尝试抓取这些子进程发生缺页异常的地址,进而定位出是什么函数导致的。下面是我用systemtap抓取以上数据的脚本:
[root@rt2k03395 bug]# cat ./cow_stat.stp
#! /usr/bin/env stap
global flags
global vma2
global address
probe kernel.statement("__handle_mm_fault@mm/memory.c:4956") {
if (execname() == "spawn.out" && pid() != $1) {
if ($vma->vm_file) {
file_name = $vma->vm_file->f_path->dentry->d_iname$;
address = $vmf->address;
flags = $vma->vm_flags;
printf("%s: %lx %s%s%s %d\n", $vma->vm_file->f_path->dentry->d_iname$, address,
flags & 0x0001 ? "r" : "-", flags & 0x0002 ? "w" : "-", flags & 0x0004 ? "x" : "-",
pid());
}
else {
address = $vmf->address;
flags = $vma->vm_flags;
printf("NULL: %lx %s%s%s %d\n", address,
flags & 0x0001 ? "r" : "-", flags & 0x0002 ? "w" : "-", flags & 0x0004 ? "x" : "-",
pid());
}
}
}脚本执行:./cow_stat.stp <parent pid>
因为要踢掉父进程产生的缺页异常,因此在执行spawn.out后,将其父进程pid给cow_stat.stp。
由于抓取的数据大部分是重复的,因此截取其中一段,如下:
"spawn.out": 420000 rw- 3468584
NULL: ffff8a83d000 rw- 3468585
"libc-2.32.so": ffff8a72f000 r-x 3468585
"ld-2.32.so": ffff8a84b000 rw- 3468585
"libc-2.32.so": ffff8a702000 r-x 3468585
NULL: ffffcafab000 rw- 3468585 <栈地址>
"spawn.out": 400000 r-x 3468585
"ld-2.32.so": ffff8a80c000 r-x 3468585
NULL: ffffcafaa000 rw- 3468585 <栈地址>
"libc-2.32.so": ffff8a688000 r-x 3468585
"libc-2.32.so": ffff8a697000 r-x 3468585
"libc-2.32.so": ffff8a6a0000 r-x 3468585上面的文件与spawn.out虚拟地址映射区间对照看:
[root@rt2k03395 bug]# cat /proc/5617/maps
00400000-00401000 r-xp 00000000 fd:10 2490372 /mnt/nvme2/bug/spawn.out
0041f000-00420000 r--p 0000f000 fd:10 2490372 /mnt/nvme2/bug/spawn.out
00420000-00421000 rw-p 00010000 fd:10 2490372 /mnt/nvme2/bug/spawn.out
ffff8a685000-ffff8a7e4000 r-xp 00000000 fd:02 791056 /usr/lib64/libc-2.32.so
ffff8a7e4000-ffff8a802000 ---p 0015f000 fd:02 791056 /usr/lib64/libc-2.32.so
ffff8a802000-ffff8a805000 r--p 0016d000 fd:02 791056 /usr/lib64/libc-2.32.so
ffff8a805000-ffff8a808000 rw-p 00170000 fd:02 791056 /usr/lib64/libc-2.32.so
ffff8a808000-ffff8a80b000 rw-p 00000000 00:00 0
ffff8a80b000-ffff8a82e000 r-xp 00000000 fd:02 791777 /usr/lib64/ld-2.32.so
ffff8a83d000-ffff8a83f000 rw-p 00000000 00:00 0
ffff8a847000-ffff8a849000 r--p 00000000 00:00 0 [vvar]
ffff8a849000-ffff8a84a000 r-xp 00000000 00:00 0 [vdso]
ffff8a84a000-ffff8a84b000 r--p 0002f000 fd:02 791777 /usr/lib64/ld-2.32.so
ffff8a84b000-ffff8a84d000 rw-p 00030000 fd:02 791777 /usr/lib64/ld-2.32.so
ffffcaf8c000-ffffcafad000 rw-p 00000000 00:00 0 [stack]上面发生缺页的,有栈地址,spawn.out数据段和代码段、ld-2.32.so数据段和代码段、以及libc-2.32.so代码段。因为子进程执行了exit(0)函数,按照经验,需要修改和更新自己的GOT表,因此spawn.out数据段的缺页很正常,同时spawn.out代码段在fork()过程中也没有执行拷贝页表过程,因此发生缺页正常。另外,子进程更新自己的GOT,会执行ld-2.32.so相关函数,所以ld-2.32.so数据段和代码段的缺页也是正常行为。
GOT相关内容可参考之前的文章:
接下来就只剩下libc-2.32.so的缺页解释了,并且根据抓取的数据,发生在libc-2.32.so上的缺页次数最多。
其实,到这里,基本可以猜到是fork()和exit()执行的代码有可能分布在几个4K区域,导致多处缺页。因此我们尝试调用跳过libc库的函数替换fork()和exit()。完全跳过libc库需要自己手写汇编,这里我们可以用syscall(SYS_fork)和syscall(SYS_exit, 0)进行简单验证,syscall()函数会进入到libc库,但是入口函数唯一,理论上再次抓取的数据中libc-2.32.so的缺页会大大减少,甚至是一个固定的地址。
接下来是我们抓取的新数据(建议在x86下验证,arm中不支持syscall(SYS_fork)):
"libc-2.30.so": 7fdcaba9d000 r-x 57931
"libc-2.30.so": 7fdcaba9d000 r-x 57931
"libc-2.30.so": 7fdcaba9d000 r-x 57931
"libc-2.30.so": 7fdcaba9d000 r-x 57931
"libc-2.30.so": 7fdcaba9d000 r-x 57931提出一些spawn.out产生的缺页后,发现libc-2.30.so产生的缺页地址固定:0x7fe82f3cf000,我们猜测这个地址是libc.so中函数syscall()的地址,可以用gdb验证一下:
#gdb spawn.out -p 83352
(gdb) disassemble syscall
Dump of assembler code for function syscall:
0x00007fdcaba9d160 <+0>: endbr64
0x00007fdcaba9d164 <+4>: mov %rdi,%rax
0x00007fdcaba9d167 <+7>: mov %rsi,%rdi
0x00007fdcaba9d16a <+10>: mov %rdx,%rsi
0x00007fdcaba9d16d <+13>: mov %rcx,%rdx
0x00007fdcaba9d170 <+16>: mov %r8,%r10
0x00007fdcaba9d173 <+19>: mov %r9,%r8
0x00007fdcaba9d176 <+22>: mov 0x8(%rsp),%r9
0x00007fdcaba9d17b <+27>: syscall
0x00007fdcaba9d17d <+29>: cmp $0xfffffffffffff001,%rax
0x00007fdcaba9d183 <+35>: jae 0x7fdcaba9d186 <syscall+38>
0x00007fdcaba9d185 <+37>: retq
0x00007fdcaba9d186 <+38>: mov 0xc5cdb(%rip),%rcx # 0x7fdcabb62e68
0x00007fdcaba9d18d <+45>: neg %eax
0x00007fdcaba9d18f <+47>: mov %eax,%fs:(%rcx)
0x00007fdcaba9d192 <+50>: or $0xffffffffffffffff,%rax
0x00007fdcaba9d196 <+54>: retq
End of assembler dump.缺页总是按照4K地址对齐缺页,0x7fdcaba9d160是函数syscall()的地址,我们前面获取0x7fdcaba9d000已经被4K对齐,正常触发缺页的第一个地址是syscall指令的下一个指令,即0x7fdcaba9d17d(可以简单修改上面的systemtap脚本验证)。
到这里,我们基本可以确定前面发生大量的缺页异常是由于子进程执行fork()和exit()触发的,其中fork()在libc.so中还会调用的函数会覆盖多个4K区域,导致了更多的缺页异常。
#perf stat -e faults -p 35353 -- sleep 10
Performance counter stats for process id '35353':
659,845 faults
10.001209323 seconds time elapsed
#perf stat -e faults -i -p 35353 -- sleep 10
Performance counter stats for process id '35353':
271,396 faults
10.001206129 seconds time elapsed上面是使用syscall(SYS_fork)和syscall(SYS_exit, 0)后,重新测量的缺页异常计数,现在的父进程/子进程 缺页中断比例:1/1.4,相比1/7,大幅度下降了5倍,完成验证。
swap - memory corruption
swap是一个Linux中典型的用时间换空间的特性,举一个简单的例子:程序A的堆栈数据占用了20G内存,由于内存不足,系统开始回收一部分冷内存,但是由于堆栈数据在磁盘没有对应的文件,无法直接写回,这时候就需要在磁盘上创建一块10G swap分区,系统就可以回收这些堆栈数据到swap分区,等程序下次访问已经swapout的堆栈数据时,会再次swapin回来。看似多了10G的内存,但swap分区的读写介质还是磁盘,速度赶内存差一大截。
有了前面的前置知识,开始讲讲这个bug故事...
最开始,这个bug是在龙蜥bugzilla【1】上暴露的,测试用例是stress-ng,【1】上提供了大约4种可用信息,是在四次测试中系统宕机前打印的警告,如下:
kernel BUG at lib/list_debug.c:26
[ 201.026658] __list_add_valid+0x74/0xa0
[ 201.027060] plist_add+0xe8/0x130
[ 201.027410] add_to_avail_list+0xc8/0x160
[ 201.027829] _enable_swap_info+0x78/0xac
[ 1490.943666] plist_check_prev_next+0x50/0x70
[ 1490.944135] plist_check_head+0x40/0xf0
[ 1490.944555] plist_requeue+0x1c/0x120
[ 1490.944960] get_swap_pages+0x19c/0x2f4
[ 1490.945384] get_swap_page+0x160/0x27c
[ 1490.945797] shmem_writepage+0x11c/0x360
[ 1366.988920] plist_check_prev_next+0x50/0x70
[ 1366.989384] plist_check_head+0x40/0xf0
[ 1366.989804] plist_add+0x28/0x140
[ 1366.990175] add_to_avail_list+0x9c/0xf0
[ 1366.990609] swap_range_free.constprop.0+0xf0/0xf4
[ 1366.991134] swapcache_free_entries+0x108/0x2d4
[ 1366.991620] free_swap_slot+0xc4/0xe4四段信息能看出啥?
- “kernel BUG at lib/list_debug.c:26”:这种事内核主动触发的,因为发现了数据的确不对劲,必须触发宕机,否则影响程序正常数据;
- 大概率和前面这个信息是一起的,__list_add_valid()这个函数会执行lib/list_debug.c:26这一行的,不过看到_enable_swap_info()开始怀疑swap;
- 不但看到了shmem swap路径,并且这个bug开始出现plist相关的路径,开始让人想:“是不是内存OOM的时候,开始进行回收触发的,因为内存大多数bug,都是因为OOM后走了fallback路径处理不当导致”;
- 这个段信息,和第3段有些相似,但是触发的入口却是free_swap_slot(),开始推翻前面OOM触发的猜测,毕竟这段和OOM关系并不大,也能触发bug;
让人叹一口气,目前的信息有点乱,心中万马奔腾。目前提供的信息还不足以让人70%确定真凶到底是swap问题、list问题还是其他踩内存的问题,这种疑问来自以下几点经验:
- swap这块的代码“好几年”没动过,不可能有bug,除非上游社区也有;
- plist和list的代码很basic,不可能有bug,要是有不得遍地开花;
整理一下思绪后,开始梳理以下几点TODO LIST逐一排查:
- 本地尝试复现,确保复现时间可容忍;
- 读前面plist、list和shmem_writepage()相关的代码,大致了解其中触发bug的逻辑,也可有助于后面重新写快速复现用例;
- 打开一些调试debug config,比如死锁、plist或者slub debug,获取更多信息;
- 验证社区是否存在,可缩小排查范围:社区补丁或我们自研补丁;
第1、4步执行后,大致确定了这个BUG社区一直存在:至少从linux-5.10到当前最新。当然复现时间略微有点长,大约30分钟~1小时不计。
第2、3步中,打开了死锁的几个调试config和CONFIG_PLIST_DEBUG,又出现了新的现象:
[ 3411.289738] ------------[ cut here ]------------
[ 3411.290558] top: 000000005c4665a9, n: 00000000af0bc8cf, p: 00000000af0bc8cf
prev: 000000005c4665a9, n: 00000000af0bc8cf, p: 00000000af0bc8cf
next: 00000000af0bc8cf, n: 00000000af0bc8cf, p: 00000000af0bc8cf
[ 3411.292512] WARNING: CPU: 1 PID: 905459 at lib/plist.c:35 plist_check_prev_next+0x50/0x70
[ 3411.293276] ...
[ 3411.296729] CPU: 1 PID: 905459 Comm: stress-ng Kdump: loaded Tainted: G 5.10.134+
[ 3411.297669] Hardware name: Alibaba Cloud Alibaba Cloud ECS
[ 3411.298416] pstate: 60400005 (nZCv daif +PAN -UAO -TCO BTYPE=--)
[ 3411.299013] pc : plist_check_prev_next+0x50/0x70
[ 3411.299489] lr : plist_check_prev_next+0x50/0x70
[ 3411.299964] ...
[ 3411.308677] Call trace:
[ 3411.308946] plist_check_prev_next+0x50/0x70
[ 3411.309400] plist_check_head+0x80/0xf0
[ 3411.309805] plist_add+0x28/0x140
[ 3411.310145] add_to_avail_list+0x9c/0xf0
[ 3411.310559] _enable_swap_info+0x78/0xb4
[ 3411.310971] __do_sys_swapon+0x918/0xa10
[ 3411.311388] __arm64_sys_swapon+0x20/0x30
[ 3411.311807] el0_svc_common+0x8c/0x220
[ 3411.312193] do_el0_svc+0x2c/0x90
[ 3411.312548] el0_svc+0x1c/0x30
[ 3411.312867] el0_sync_handler+0xa8/0xb0
[ 3411.313276] el0_sync+0x148/0x180
[ 3411.313655] ...
[ 3411.317543] ---[ end trace 13b265c7d29c5cf7 ]---
[ 3540.070679] watchdog: BUG: soft lockup - CPU#1 stuck for 134s! [stress-ng:905459]
[ 3540.091789] watchdog: BUG: soft lockup - CPU#9 stuck for 134s! [stress-ng:905460]为了方便排版,上面的栈回溯踢出了一些不相干的信息。这里大致说明一下上面的提供的信息:
- “BUG: soft lockup - CPU#1 stuck for 134s!”:有可能是死锁,或者是CPU1进入了死循环,stuck时间超过阈值后,在定时器中断里边会主动触发PANIC;
- 第2行打印:定位到时函数plist_check_prev_next()的行为,根据这个基本确定前面soft lockup是plist_check_list()中while()循环一直未退出导致;
经过多次测试,每次基本都打印了上面的信息,到此,可以确定:
问题:该BUG触发的前面一系列宕机前的异常打印都是由于plist链表出现异常导致。通过分析plist_check_list()代码,进一步笃定第一现场是因为top->next指向next,但是next->prev、next->next却指向自己,因此才导致了plist_check_list()中while()死循环。
其实,走到这里,这个怪异的BUG才刚刚开始...
到底是什么原因才会导致上面top、next两个节点指向异常,或者为什么next总是指向自己,不是指向另一个节点?案情似乎又走到了死胡同。不得不再次回到前面梳理的TODO LIST,开始按照宕机信息,手动复现BUG,猜测复现的场景:多并发频繁的swapoff-swapon一个分区,同时多并发对一段shared memory进行madvise(MADV_PAGEOUT)操作。在32 cores的虚拟机上,以上两种行为各跑了16~32个进程,最终保证在2分钟内触发该BUG。到此,基本可以确定“频繁的swapon-swapoff操作 与 shared memory的swapout操作”导致了该BUG。
接下来,开始投入到swapon()和swapoff()函数代码中...由于对swap的机制并非特别熟悉,到此才发现swapoff关闭的swap分区,其主要的对象swap_info_struct所占的内存,并不会回收,而是一直保留在swap_info[]数组中,直接给下一次swapon()时使用。结合盯着swapoff()代码几个小时的经验:swapoff()中del_from_avail_list()持有的锁有点奇怪,二是swapoff()执行过程中,也有可能swap分区关闭失败,大胆猜测是swapoff()执行过程中,因为对swap_info_struct持有的锁有间断的行为,被其他待执行add_to_avail_list()的进程截胡了。swapoff()继续处理该swap_info_struct,且让swapon()下次可以申请该swap_info_struct内存为新的swap分区使用(参考alloc_swap_info())。而前面top/next问题,就是因为该swap_info_struct内存还在某个链表上使用,而swapon()中又会初始化该swap_info_struct,导致了next的prev/next会到了初始化状态,而top->next任然指向它,相当于是一个memory corruption问题。
这个竞争过程可以描绘成:
core 0 core 1
swapoff
del_from_avail_list(p) waiting
try lock p->lock acquire swap_avail_lock and
add p into swap_avail_head again
acquire p->lock but
missing p already be
added again, and continuing
to clear SWP_WRITEOK, etc.为了验证猜测,简单修改了一下代码,用手动写的测试用例压了1~2个小时未能触发,基本确定了以上便是root-cause。相关的bugfix已经合入龙蜥社区【2】以及Linux社区【3】
最后小结一下,最开始就怀疑到是swap_info_struct锁的问题,因为相关的锁有点乱,居然有三把锁管理:swap_lock、swap_info_struct.lock和swap_avail_lock,但是经管猜测到时锁的问题,还是没办法确定具体的root-cause。同时,该BUG也补上了对spinlock的认知:一直以为是先到先得,其实也有可能是后到先得,比如优先考虑同节点其他CPU优先持有锁,然后再是其他节点的CPU。
链接:
【1】 https://bugzilla.openanolis.cn/show_bug.cgi?id=4602
【2】https://gitee.com/anolis/cloud-kernel/pulls/1528
【3】mm/swap: fix swap_info_struct race between swapoff and get_swap_pages()
零页:缓存着色问题
首先从一组测试数据讲起:构建32个线程对同一个数组并发读操作,不同线程读数组不同偏移部分,然后测试L1 dcache数据。
下面是perf抓取的数据,
不绑核
Performance counter stats for './a.out':
4,186,720,441 L1-dcache-load-misses # 2.91% of all L1-dcache accesses
143,968,146,098 L1-dcache-loads
6.729459717 seconds time elapsed
53.766384000 seconds user
0.008000000 seconds sys上面测试用例的L1 dcache miss达到2.9%,结合我们实际测试的每核读取的数据一直是4k大小,因此这2.9%有点反常。
上面的测试用例是在发现当前几乎所有arm机器的L1 cache是64k以后,为验证猜测所写。在描述猜测前,先插播一段众所周知关于cache别名问题的描述:
以往,我们都在x86机器上进行开发,x86的L1 cache都比较熟悉,几乎都是32K大小,其路数大概是8 way,即每路大小是4K。这里每路设计成4K可以简单认为就是为了避免cache别名问题(不同虚拟地址,命中同样的物理页帧)。根据cache设计,一旦每路大小超过4K,肯定存在别名问题。
当前,我们在用的较广泛的两种ARM机器(鲲鹏和倚天)上查看,其L1 dcache每路大小为16K,为了避免别名问题,在L1-L2中肯定设计了某种方式(《超标量处理器设计/P92》中提到两种解决方法:一是bank cache,二是利用L2 cache检查,当前大多采用第二种方式)。
如何查看机器的cache信息:
cd /sys/devices/system/cpu/cpu0/cache/index0
其中包括cache大小、路和组信息以及core信息。
因此,采用L2 cache来解决别名问题,会反复了驱逐不同核上缓存该数据的cache line,反映在用户态,就会有较高的L1 dcache miss。如果验证这个猜测,我们可以构建一个用例:同一个进程的不同线程访问同一个物理页,比如零页,或者对同一个文件映射多次,这里我们选择零页。另外,我们也尝试在Linux内核中来解决这种问题,对于零页,可以按照下面的方式分配:
PAGE_MASK (0xFFFxxxFFF 000)
zero_page_mask = ((PAGE_SIZE << order) - 1) & PAGE_MASK;
+#define ZERO_PAGE(vaddr) \
+ (virt_to_page((void *)(empty_zero_page + \
+ (((unsigned long)(vaddr)) & zero_page_mask))))对于cache=64k,zero_page_mask = 0xF000(12-15保留),即根据发生缺页地址的bit12-bit15分配不同的零页,相当于对于4K页,这里存在16个零页。正好将多出引起cache alias问题的4bits用于挑选不同的零页。
该想法已经被redhat很早发在了社区,目前没有合入:
https://lore.kernel.org/linux-arm-kernel/20200916032523.13011-1-gshan@redhat.com/
加上color zero page,我们再次进行测试:
Performance counter stats for 'numactl -C 1 ./a.out':
346,631,377 L1-dcache-load-misses # 0.24% of all L1-dcache accesses
143,708,549,175 L1-dcache-loads
54.743027341 seconds time elapsed
50.599881000 seconds user
0.003697000 seconds sysdcache miss优化挺大,直接下降了10倍。
该数据说明:
- ARM的机器在L1 dcache上的确存在别名问题,但是是通过L2 cache来解决,可以通过零页来触发;
- 除了零页,不同地址映射相同的文件偏移,肯定存在同样的问题,但是想验证这种页,在内核中实现难度较大,或者没有太大意见去解决这类问题。
tlb_flush1_processes抖动
tlb_flush1_processes是will-it-scale测试集中的一个压测用例,其具体测试的模型大致可以描述成:touch-madvise(dontneed),即访问一次内存,同时对该内存执行一次madvise(dontneed)操作。从OS内核的角度,上述过程会不断的申请内存,然后又不断的遍历页表取消内存映射(上述过程详述过于复杂,此处略)。个人理解这个测试用例测试的系统申请内存和madvise()的弹性能力(可以调节不同的进程数压测),一秒钟内存touch-madvise(dontneed)重复的次数越大,性能当然越好。
这里描述的问题是我们引入社区memcg lru lock(阿里自研特性)优化后,该用例在并发度打满的情况下出现性能回退,经过我们一顿骚操作,cacheline对齐lruvec->lock后,还剩下10%左右的性能回退。本文就想看看剩余的10%产生的原因。
为了搞清楚上面的原因,分别在NUMA关闭和打开的环境进行测试,同时为了进一步确定锁的原因,通过perf lock确定了一下锁的竞争延迟。
为了描述简单,使用NOLRU表示优化前版本,LRU表示引入社区memcg lru lock优化后版本。
关闭NUMA vs 打开NUMA
测试环境:arm机器,96核。
关闭NUMA | NO LRU | LRU |
default memcg | 341110 | 325048 |
test memcg | 338933 | 325096 |
打开NUMA(4个节点) | ||
default memcg | 1390572 | 1365163 |
test memcg | 1341377 | 1414621 |
测试命令:./tlb_flush1_processes -t 96 -s 30
关闭NUMA的热点:
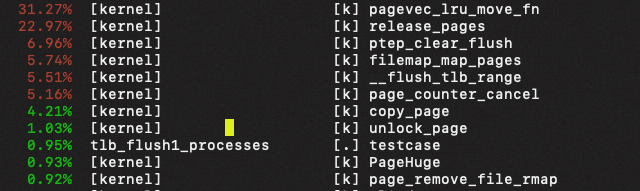
打开NUMA后的热点:
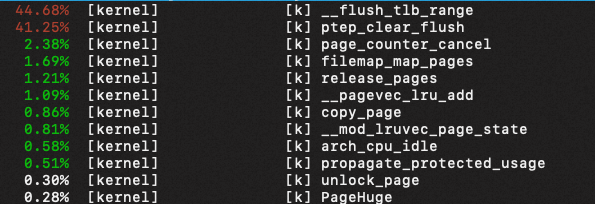
分析:
- 关闭NUMA时:
- pgdat->lru_lock锁的热点占37%;(NUMA关闭的情况下,同一个node的页,该锁是同一个,所以争抢肯定严重)
- 以上这些热点在NUMA打开后基本消失,说明还是与pgdat有关;
- 打开NUMA后:
- LRU与NO LRU在该用例上基本没有性能差异,LRU反而略优于NO LRU;
- 打开NUMA,整体比关NUMA性能好四倍,可以认为打开NUMA后,一个memcg对应四个lruvec,所以锁竞争降低四倍,符合预期;
- 关闭NUMA,性能约差4%,不是很大。
注:madvise()过程会调用lru_drain_cpu(),触发native_queued_spin_lock_slowpath(注:lru和nolru该锁不一样)。在arm机器上cmdline加上irqchip.gicv3_pseudo_nmi=1可以显示以上热点。
同时,这里进一步探索并发度和percpu的算力拐点。
首先进行48并发度测试和96并发度对比,压力下降一倍,性能提升30%左右,抖动也消失,可以说明上面的分析1的权重较大;
尝试持续测试./tlb_flush1_processes -t T -s 5,发现当前T=10时,average达到最大(粗略),可以认为该锁承受压力的拐点为10;当超过10,算力反而在降低。这个时候percpu算力几乎也达到的最大值。
锁竞争测试
紧接上面的测试,继续分析关闭NUMA时,LRU和NO LRU的锁竞争对比。
测试对象:LRU+关闭NUMA
- 17.03% 17.03% [kernel] [k] native_queued_spin_lock_slowpath ▒
15.86% _start ▒
__libc_start_main ▒
main ▒
- new_task_affinity ▒
- 16.82% __madvise ▒
el0_sync ▒
el0_sync_handler ▒
el0_svc ▒
do_el0_svc ▒
el0_svc_common ▒
__arm64_sys_madvise ▒
do_madvise ▒
- zap_page_range ▒
- 8.47% tlb_finish_mmu ▒
free_pages_and_swap_cache ▒
release_pages ▒
lock_page_lruvec_irqsave ▒
_raw_spin_lock_irqsave ▒
native_queued_spin_lock_slowpath ▒
- 8.36% lru_add_drain ▒
lru_add_drain_cpu ▒
__pagevec_lru_add ▒
lock_page_lruvec_irqsave ▒
_raw_spin_lock_irqsave ▒
native_queued_spin_lock_slowpathLRU+关NUMA情况下使用perf lock抓取的锁相关的延迟:
Name acquired contended avg wait (ns) total wait (ns) max wait (ns) min wait (ns)
&type->i_mutex_d... 190 131 10742281 1407238940 16916170 710320
&pipe->rd_wait 193 66 335779 22161450 447700 245790
&page_wait_table... 148 139 112161 15590480 230910 1870
&page_wait_table... 27 9 36191 325720 62230 12910
&zone->lock 2847 379 11629 4407700 238230 1440
&page_wait_table... 28 5 11408 57040 46170 2060
&page_wait_table... 107 42 6225 261490 46270 1530
&lruvec->lru_loc... 15 1 4430 4430 4430 4430
&type->i_mutex_dir_key
&pipe->rd_wait
0xffff80001161e458: &page_wait_table[i]测试命令:
perf lock record -v ./tlb_flush1_processes -t 96 -s 5
perf lock report -k avg_wait
对于NOLRU,在NUMA打开的情况下抓去上面的数据,多次测试并没有发现&lruvec->lru_lock(看来要达到某个阈值,才能抓?)。
从上面的数据,排除一些与本实验无关的锁,可以看到&zone->lock和&lruvec->lru_lock两把等待时间较长的锁。其中&zone->lock在分配内存的时候需要获取。