由SnpUniqueFwd和SnpUnique混合使用引发的思考
一致性与内存屏障:一场在CHI总线上的花活
前几日,在 xhs 上刷到一则颇有意思的讨论:关于SnpUniqueFwd和SnpUnique混合使用的话题,以及这种混用究竟会在底层引发什么灾难性的影响。这个案例用来理解内存一致性、缓存一致性和可见性的关系非常有价值。在讨论这个哑谜之前,先得理清这两个概念的底牌是什么。
Coherence(缓存一致性)和 Consistency(内存一致性)有点关系,但不好说清。就拿王者荣耀举个例子:Coherence 就像是红蓝 Buff 的存活状态,不管玩家的网络延迟有多大,只要红 Buff 被打掉了,所有人最终看到这个野怪坑位肯定都是空的。这是Coherence 加持后的结果;而 Consistency 关乎的是因果律,它就像是英雄的连招顺序。比如对面打野先闪现(动作 1),再放大招秒人(动作 2)。被虐的玩家不应该看到:自己先掉血被秒了,然后对面打野才闪现过来。两个动作前后关系由Consistency 规定,但是每个动作能正常执行都必须依赖Coherence。
在多核架构的世界里,缓存分布在不同的核心上,依赖监听事务去同步。SnpUnique是一种非转发类型的监听请求(Non-forwarding snoop),为了获取缓存行的独占(Unique)副本,它会严谨地要求系统内所有持有该副本的节点立刻将缓存销毁(作废缓存,强制转换为 Invalid (I) 态)。属于妥妥的保守派。SnpUniqueFwd(Forwarding snoop),则是前者的“激进派”变体。它同样是为了拿独占权并使其他节点失效,但它带了一个“特权”——指示被监听节点将缓存行直接转发(DCT)给原始发起请求的核心。没有中间商赚差价,包裹直接快递到家,而不是先到总仓。但这有个严格规定:SnpUniqueFwd仅允许在该缓存行只被单个RNF缓存时使用。

所以,以ReadUnique为例,HNF 节点如果发现有多个节点都有该数据的缓存时,能不能玩个花活?给其中一个 RN 发 SnpUniqueFwd,同时给其他的 RN 发常规的 SnpUnique?
这么干的立场很明显:为了压榨那哪怕千分之一的性能。如果可以这么发,被发SnpUniqueFwd的 RNF 即可直接 DCT 将数据甩给原 RNF 请求节点,避免了SnpUnique那套又长又臭的流程(数据先从 RNF 吐给 HNF,再由 HNF 转交到目标 RNF)。
为什么混搭会导致已读乱回?
备注:网络原图链接暂时未找到。
原文讨论很清晰,现实的铁拳告诉你:不能。
一个是CHI协议规定只有在单个RN有数据时才能发SnpUniqueFwd。当多个RN拥有S态时,为什么不能SnpUniqueFwd和SnpUnique一起往外发?因为SnpUniqueFwd返回的CompData 直接有可见的语义,而在SnpUnique 中,可见必须要等到所有的snp Invalidate都完成才能返回,但是这里的CompData通过DCT返回,并不会等其他的SnpUnique的完成。如果SnpUniqueFwd 比其他SnpUnique 提前完成并返回了CompData。这就告诉了 barrier 一个错误的信号,前面的指令已经可见,后续的指令可以唤醒执行。
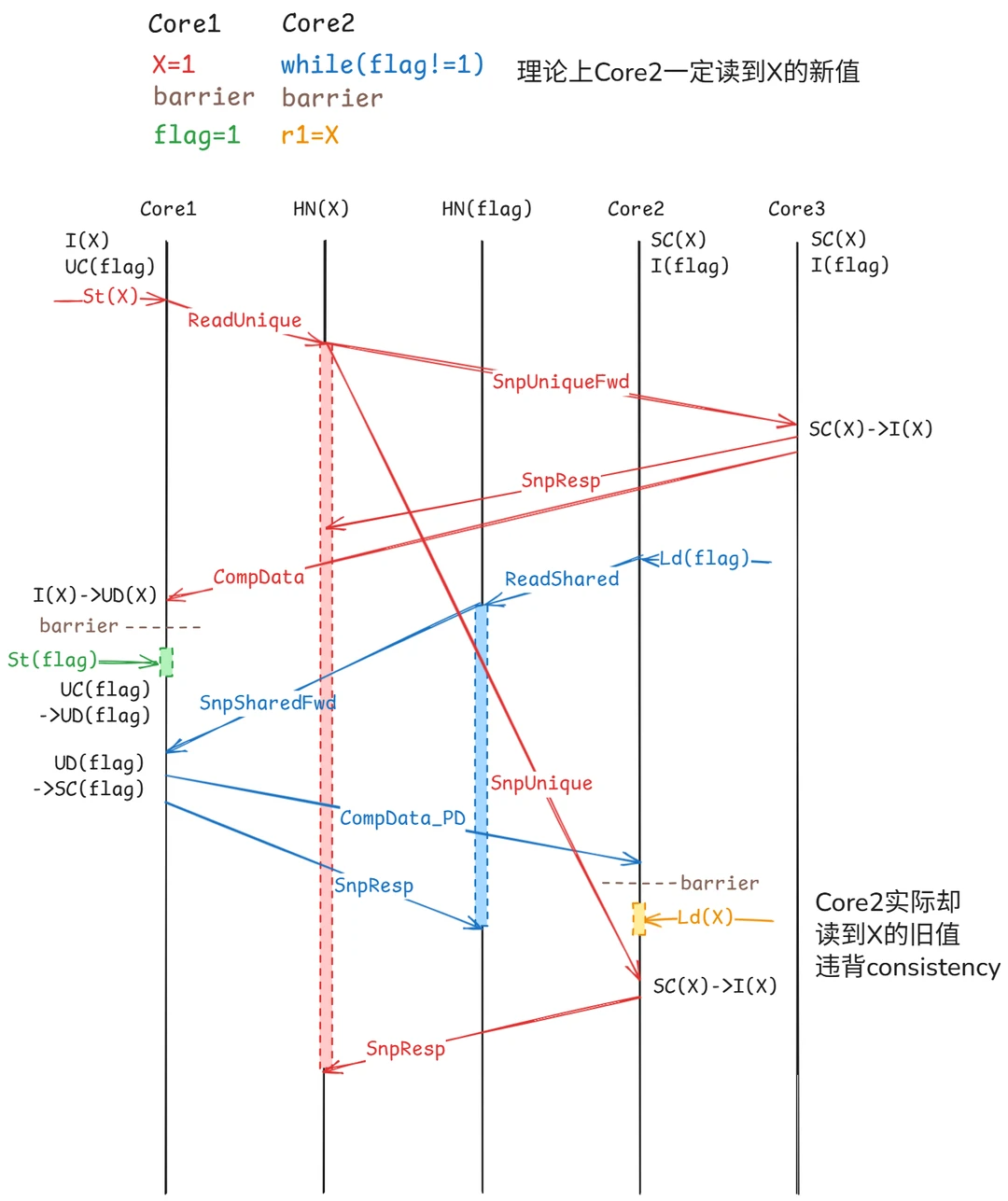
看上去并没什么影响,原文举了一个简单的案例(如上图)。在初始状态,X 在 3 个 core 有缓存并处于共享状态,SnpUniqueFwd 提前返回,但SnpUnique 还未完成,在 core2 收到SnpUnique 前,core2 发起了一次读事务,错误就产生了,直接读到了 X 的旧值。原文未提到的一点是,这直接破坏了内存屏障的语义,r1 肯定是能读到最新的 X,但实际有可能读不到。最终,这个小小的取巧操作,把整个系统的 Consistency给炸穿了。
这个案例最有意思的一点是可以用来理解 coherence、可见性和consistency三者的关系。coherence 乱一点,consistency 就闹翻了天,整个系统的时间线就乱了,成了真正的已读乱回。。。
本文的目标是补充一些先验知识,以便更通透的了解整个案例。将案例中涉及的可见性、CompData 展开聊聊,光说无味,尤其需要搬出 CMN 中在面对几种 barrier 是如何处理可见性的,方便理解。
内存屏障
ARMv8提供如下指令来实现ordering。ARM64在内核最常使用dmb/dsb/isb/ldar&stlr指令来实现ordering,也定义了一些在其它特殊场景使用的barries。
//ARM64下定义的内存屏障指令
#define isb() asm volatile("isb" : : : "memory")
#define dmb(opt) asm volatile("dmb " #opt : : : "memory")
#define dsb(opt) asm volatile("dsb " #opt : : : "memory")
#define psb_csync() asm volatile("hint #17" : : : "memory")
#define csdb() asm volatile("hint #20" : : : "memory")
#define mb() dsb(sy)
#define rmb() dsb(ld)
#define wmb() dsb(st)
#define dma_rmb() dmb(oshld)
#define dma_wmb() dmb(oshst)
#define __smp_mb() dmb(ish)
#define __smp_rmb() dmb(ishld)
#define __smp_wmb() dmb(ishst)
#define __smp_store_release(p, v) ...
#define __smp_load_acquire(p) ...当前 Linux arm64 设计中,所有 cpu core 属于一个Inner Shareable domain,相当于smp_rmb()会广播到其他 core。
DMB指令:只要看见了就行
该指令保证dmb指令前后的memory access的顺序(ordring),其他指令还是会乱序。
(1)DMB指令的作用
- DMB指令只影响显示的memory data access ordering(注意:这里data access也包括显示的data cache操作);
- DMB指令确保DMB指令之前的内存访问在DMB指令之后的内存访问之前被可见(observed),不能确保DMB指令之前的memory access一定在DMB指令结束之前完成(completion)。这其实就是一个投机行为,只要在某个关键节点完成后,保证了序的要求,DMB 的使命就算完成了,一切为了性能嘛。
什么是observed?什么是completion?以 CHI 中分配读事务(store 操作也可能需要先发一次读事务)为例,收到 Home 节点返回的:
- CompData:响应和数据同时打包,也有observed 语义;
- RespSepData:Home 节点告诉你“我已经处理好了,但还没完全弄完”,但这已经满足了“序”的要求。于是它暗示 RNF 节点:“你可以继续发同一个核心、同一个目标的后续消息了”。比如一个核执行两条 load 指令,中间加了 DMB,且读的内存在同一节点,只要 load1 返回了 RespSepData,load2 就可以立刻发射出去,不用死等。
至于 completion,它通常是在更后端、更严苛的阶段,意味着这条指令在流水线里已经彻底 Retired了。
实际的 CHI 工程实现中,各家玩儿法可能略有不同。比如在 CMN 中,为了稳妥起见,它往往只挑了CompData这种作为可见性的标准。下文的 CMN700 RTL 源码里我们会细细品味。

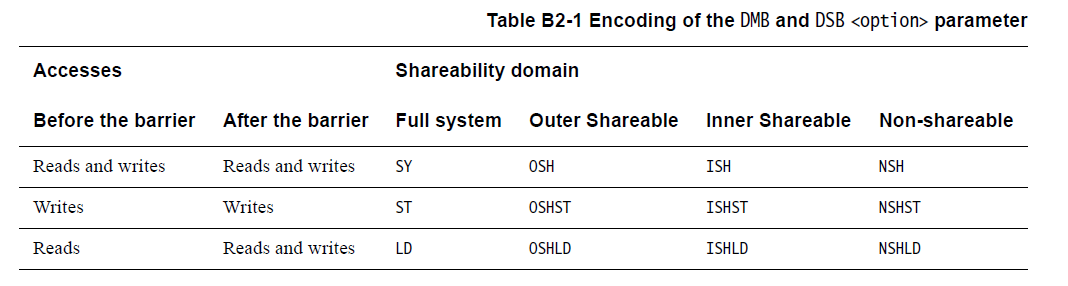
(2)DMB指令的参数
DMB指令可以作用于读操作,写操作或者读写操作。对于shareability domain的作用范围可以:full system > outer shareable >inner shareable。
(3)DMB指令示例
示例1:
LDR X0, [X1] //执行下面的STR指令之前,LDR的结果必须被observed
DMB SY
ADD X2, #1 //DMB不影响其它非memory data access操作,add指令可以越过dmb被乱序执行
STR X3, [X4] //STR的结果必须在LDR指令之后被observed
示例2:
DC CVAC, X5
LDR X0, [X1] //该指令结果必须在下面的LDR指令之前被observed
//但是此时data cache clean结果可能不会被observed
DMB SY
LDR X2, [X3] //该指令的结果必须在前边的LDR指令结束之后才被observed
//data cache clean无法跨越dmb,结果会在这里被observed(4)smp_mb/smp_rmb/smp_wmb
Inner shareable dmb指令。
(5)dma_rmb和dma_wmb
主要是实现outer shareable的dmb指令。主要是用于CPU和一些外设的DMA操作之间的数据一致性,比如GPU发起的内存访问,一般属于outer shareability,此时使用inner shareable dmb指令,则是无法达到同步效果的,等于给对方打电话,人家根本接不到。
DSB指令:不见兔子不撒鹰的“刻板官僚”
比起 DMB 的圆滑投机,DSB(Data Synchronization Barrier)就是个极度刻板的官僚。它确保在 DSB 指令结束之前,它前面的 memory access 操作必须全部、彻底地completed。DSB 屏障之后的所有指令绝对不可越过雷池一步。
1)DSB作用
- DSB指令结束之前,DSB后面的任何指令或者显示的内存访问都不会被发起执行。
- 所有的内存访问在DSB之前必须完成(completed)。
- 所有当前PE的cache, branch predictor and TLB maintenance在DSB之前必须完成(completed)。
2)DSB参数
与DMB指令参数一样。
3)DSB示例
DC ISW //在DSB指令结束之前,该操作必须结束
STR X0, [X1] //在DSB指令结束之前,该memory access必须结束
DSB SY
ADD X2, X2, #3 //在DSB指令结束之前,该操作不会被提交执行为了彻底“完成”,在硬件底层,DSB 信号需要等待的信号那是浩如烟海。我们来看看这本“直肠子硬件工程师的心酸账本”:
assign dealloc = valid_q & // 1. 本身是个有效的事务
(needs_txreq_q[2:0]==3'b000) & // 2. 发往总线的请求(Req)已经全部发完
(needs_txrsp_q==1'b0) & // 3. 发往总线的应答(如 CompAck)已经发完
(needs_wr_dat_q==1'b0) & // 4. 发往总线的写数据(Write Data)已经发完
(needs_snp_dat_q==1'b0) & // 5. 回复给总线的嗅探数据(Snoop Data)已经发完
(needs_snp_q[1:0]==2'b00) & // 6. 内部向其他核心发起的 Snoop 动作已结束
(needs_sync_q[1:0]==2'b00) & // 7. 内部同步动作结束
(needs_comp_dat_q==1'b0) & // 8. 已经收齐了来自总线的 Comp(完成)和 Data(数据)
(needs_fill_q[1:0]==2'b00) & // 9. 如果是读未命中,Cache 的数据填充(Fill)已完成
(needs_fwd_q[2:0]==3'b000) & // 10. 数据转发(Forward)操作已完成
(needs_retry_q[1:0]==2'b00) & // 11. 没有悬挂的 Retry(重试)
(needs_tag_check_q[1:0]==2'b00) & // 12. 内存标签检查(MTE Tag Check)已完成
(needs_compcmo_q==1'b0) & // 13. 缓存维护操作 (CMO) 的专用完成信号已收到
~((type_q[6:0]==`PERSEUS_LSL2_TYPE_DVMSYNC) & ~sync_op_done_ok) & // 14. 重点:如果是 TLBI 的 DVMSync,必须完全同步完毕
~snp_skid_block_dealloc & // 15. 没有被 Snoop 阻塞
~upd_victim & // 16. 没有正在更新的驱逐受害者(Victim)
~txdat_pend_entry_q; // 17. 发送数据通道没有积压从 LSU 译码发现为 DSB 到 CMN 总线的闭环到返回 LSU 的信号链大致为:
- LSU 译码出
PERSEUS_LS_TYPE_DSB置起rst_dsb并等待成为mb_dsb_oldest。 - L2 TQ 处理前序 Store,状态机清零,触发内部
dealloc。 - L2 将
dealloc编码为物理接口信号sb_raw_dealloc_ptr传回给 LSU。 - LSU 的 SAB 模块收到指针,触发
sb_deallocate_any_w2_q,在本地划掉该 Store。 - LSU 发现账本清空,置起
rst_dsb_op_done,DSB 执行完毕,闭环。
ISB指令:清道夫
ISB 指令是最极端的,它会暴躁地清洗整条流水线(CPU pipeline 和 prefetch buffer),以此保证它前面的指令彻底执行完后,才开始碰后面的指令。一般用在 Context-changing。
ISB 与 DSB 相似,但它更多是 Core 内部的一个重型行为。毕竟 CHI 互联总线能返回的消息也就那些了,而 DSB 和 ISB 因为其严苛的本性,在内部苦熬等待的流水线信号远比总线信号要多得多。
one-way barriers(单向屏障):执拗门卫与谦让绅士
有时候全面屏障太重了,于是架构师搞出了轻量级的单向屏障。我们可以用“执拗的门卫”与“谦让的绅士”来比喻。
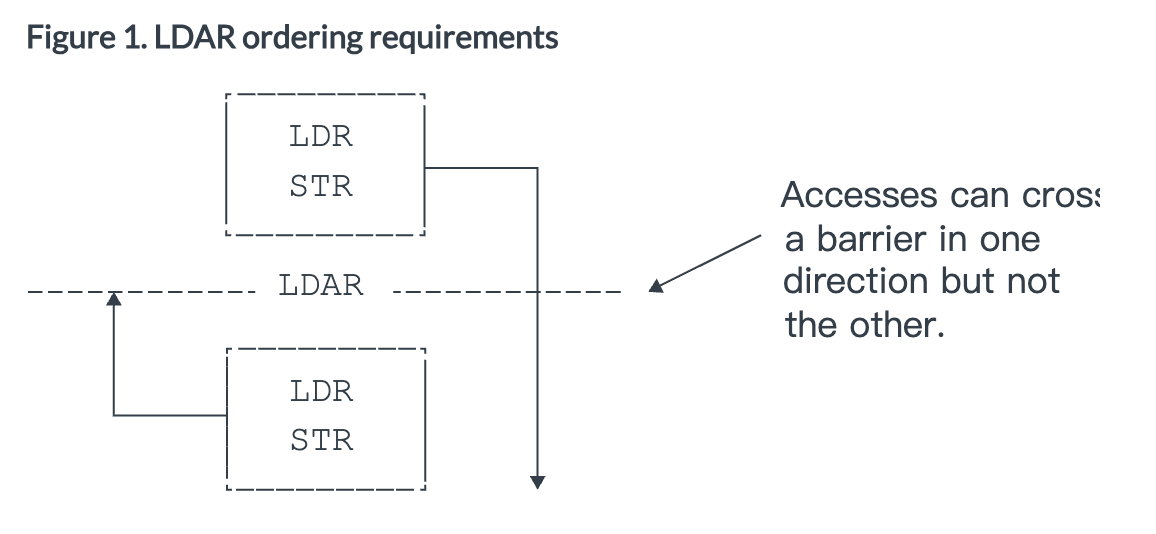
1)Load-Acquire (LDAR)
- All accesses after the LDAR are observed after the LDAR
- Accesses before the LDAR are not affected
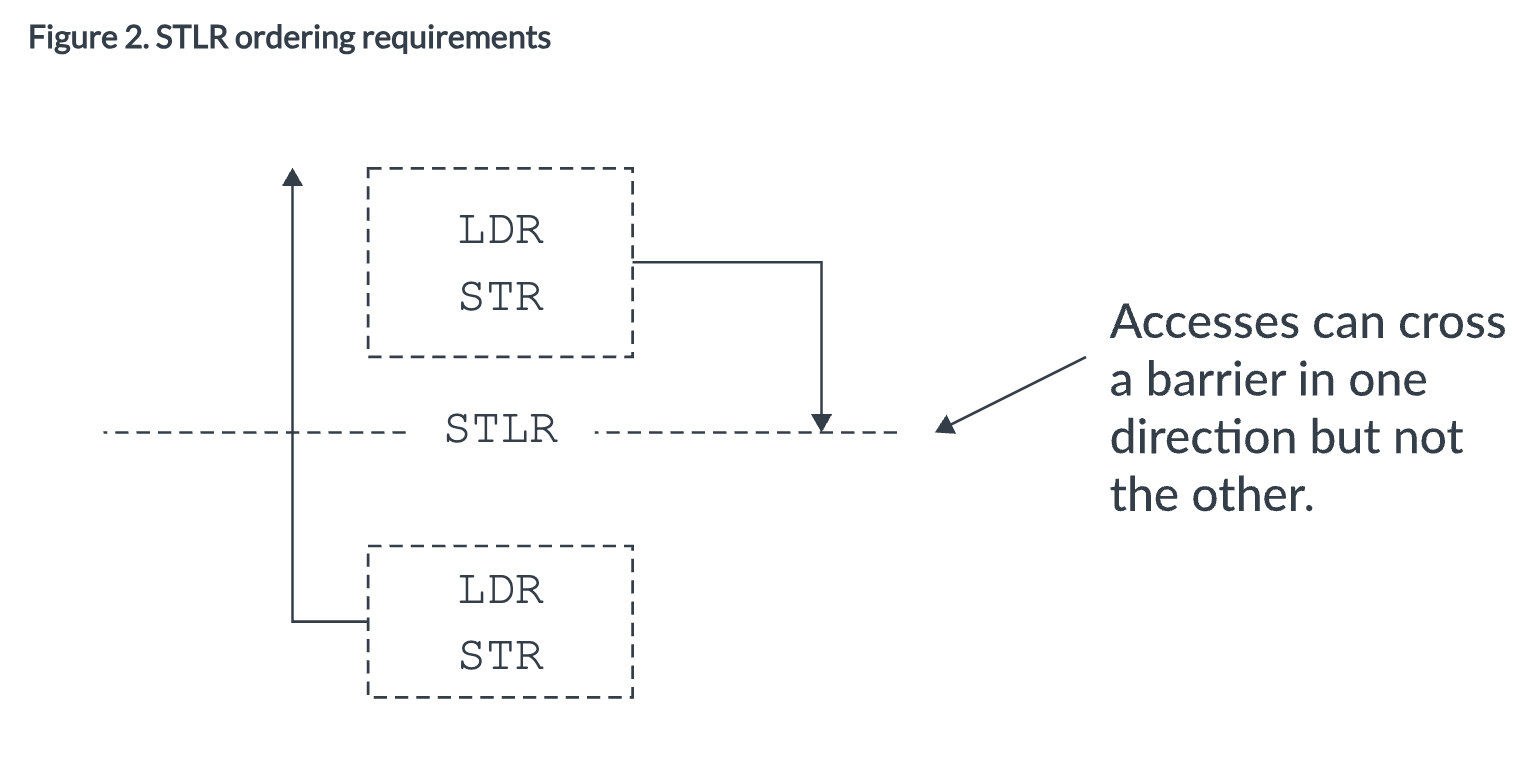
2)Store -Release (STLR)
- All accesses before the STLR are observed before the STLR
- Accesses after the STLR are not affected
参考:https://developer.arm.com/documentation/102336/0100/Load-Acquire-and-Store-Release-instructions
ld_nc_dev_wakeup 信号很大,仅列出需要的部分:
// 一个普通的访存请求想要被唤醒 (Wakeup) 发往 L2,必须满足:
assign ld_nc_dev_wakeup = (lrq_state_q[`PERSEUS_LS_LRQ_STATE] == `PERSEUS_LS_LRQ_STATE_WAIT_OLD_PRECOMMIT) &
// ... 省略其他条件 ...
~lrq_entry_older_ld_acquire_vld & // <--- 核心拦截点!
// ...为了知道一个访存请求前面是否还有一个 ld acquire未完成,Core 内部不得不用一堆极其费硅的结构来记录 load 指令进入时间的先后关系,判断谁老谁年轻(older_than_entry0~15):
assign lrq_entry15_older_ld_acquire[0] = lrq_vld_q[0] & lrq_entry_ld_acquire[0] & older_than_entry15[0] ;
assign lrq_entry15_older_ld_acquire[1] = lrq_vld_q[1] & lrq_entry_ld_acquire[1] & older_than_entry15[1] ;
assign lrq_entry15_older_ld_acquire[2] = lrq_vld_q[2] & lrq_entry_ld_acquire[2] & older_than_entry15[2] ;
assign lrq_entry15_older_ld_acquire[3] = lrq_vld_q[3] & lrq_entry_ld_acquire[3] & older_than_entry15[3] ;
assign lrq_entry15_older_ld_acquire[4] = lrq_vld_q[4] & lrq_entry_ld_acquire[4] & older_than_entry15[4] ;
assign lrq_entry15_older_ld_acquire[5] = lrq_vld_q[5] & lrq_entry_ld_acquire[5] & older_than_entry15[5] ;
assign lrq_entry15_older_ld_acquire[6] = lrq_vld_q[6] & lrq_entry_ld_acquire[6] & older_than_entry15[6] ;
assign lrq_entry15_older_ld_acquire[7] = lrq_vld_q[7] & lrq_entry_ld_acquire[7] & older_than_entry15[7] ;
assign lrq_entry15_older_ld_acquire[8] = lrq_vld_q[8] & lrq_entry_ld_acquire[8] & older_than_entry15[8] ;
assign lrq_entry15_older_ld_acquire[9] = lrq_vld_q[9] & lrq_entry_ld_acquire[9] & older_than_entry15[9] ;
assign lrq_entry15_older_ld_acquire[10] = lrq_vld_q[10] & lrq_entry_ld_acquire[10] & older_than_entry15[10] ;
assign lrq_entry15_older_ld_acquire[11] = lrq_vld_q[11] & lrq_entry_ld_acquire[11] & older_than_entry15[11] ;
assign lrq_entry15_older_ld_acquire[12] = lrq_vld_q[12] & lrq_entry_ld_acquire[12] & older_than_entry15[12] ;
assign lrq_entry15_older_ld_acquire[13] = lrq_vld_q[13] & lrq_entry_ld_acquire[13] & older_than_entry15[13] ;
assign lrq_entry15_older_ld_acquire[14] = lrq_vld_q[14] & lrq_entry_ld_acquire[14] & older_than_entry15[14] ;
assign lrq_entry15_older_ld_acquire[15] = lrq_vld_q[15] & lrq_entry_ld_acquire[15] & older_than_entry15[15] ;
assign lrq_entry_older_ld_acquire_vld[15] = (|lrq_entry15_older_ld_acquire[`PERSEUS_LS_LRQ_RANGE]) & lrq_vld_q[15] ;只要有一个lrq_entry_older_ld_acquire_vld 为高,说明前面还有一个 older LDAR 未执行,所以这个 load 就不能被唤醒发到 L2。而STLR,则是它自己在发往 L2 前,等前面的已经可见(observed)。 一个是后面的访存指令等 LDAR,一个是 STLR 等前面的访存指令。总结一下:
LDAR利用~lrq_entry_older_ld_acquire_vld像一堵单向的墙,把队列后面的访存指令挡住,但队列前面的该发还是发。STLR利用rst_stlr像一个谦让的绅士,它自己不急着出门,一定要等排在自己前面的所有人(Older Entries)都安全抵达对岸(收到Comp信号)后,自己才踏出大门。至于后面的人,早就绕过他出门了。
单向屏障,说白了就是强迫症架构师在“乱序执行的自由”和“保序的严谨”之间,非得硬生生挤出那么一丁点性能的畸形产物。另外,需要强调一下,这里的等待,等的是前面访存指令的 observed,而不是那种拖泥带水的 completion。
其他边缘的内存屏障
SB指令
Speculation Barrier。
CSDB指令
Consumption of Speculative Data Barrier。
SSBB指令
Speculative Store Bypass Barrier。
PSB CSYNC指令
Profiling Synchronization Barrier。
PSSBB指令
Physical Speculative Store Bypass Barrier。
TSB CSYNC指令
Trace Synchronization Barrier。
这些指令先一笔带过,暂时不重要。
CMN700内存屏障实现
从纸面的指令集,下沉到 RTL 的代码。下面是 L2 Transaction Queue 中依赖清除逻辑,主要说明了指令和保序组合。
assign tq_dep_clr[i][L2_TQ_SIZE-1:0] = dealloc[L2_TQ_SIZE-1:0] |
~tq_valid_q[L2_TQ_SIZE-1:0] |
fill_done[L2_TQ_SIZE-1:0] |
({L2_TQ_SIZE{tq_owner_snp[i] & tq_retry_pend[i]}} & ~tq_snp_coll_haz_en[L2_TQ_SIZE-1:0]) |
({L2_TQ_SIZE{tq_fill_retry[i] & ~fill_done[i]}} & ~tq_avoid_victim[L2_TQ_SIZE-1:0]) |
({L2_TQ_SIZE{~tq_dev_nc[i]}} & ( rxdat_flit_valid[L2_TQ_SIZE-1:0] |
(tq_rxrsp_dbidrespord[L2_TQ_SIZE-1:0] & ~needs_compcmo_q[L2_TQ_SIZE-1:0]) |
(tq_rxrsp_comp[L2_TQ_SIZE-1:0] & ~needs_compcmo_q[L2_TQ_SIZE-1:0]) |
(tq_rxrsp_compdbidresp[L2_TQ_SIZE-1:0] & ~needs_compcmo_q[L2_TQ_SIZE-1:0]) |
(tq_rxrsp_comppersist[L2_TQ_SIZE-1:0] & ~needs_compcmo_q[L2_TQ_SIZE-1:0]) |
(tq_rxrsp_compcmo[L2_TQ_SIZE-1:0] & needs_compcmo_q[L2_TQ_SIZE-1:0] & ~tq_needs_txreq[L2_TQ_SIZE-1:0]) |
(tq_rxrsp_comppersist[L2_TQ_SIZE-1:0] & needs_compcmo_q[L2_TQ_SIZE-1:0] & ~tq_needs_txreq[L2_TQ_SIZE-1:0]) )) |
({L2_TQ_SIZE{tq_dev_nc[i] & ~tq_dvmsync[i]}} & ( tq_rxrsp_readreceipt[L2_TQ_SIZE-1:0] |
rxdat_flit_valid[L2_TQ_SIZE-1:0] |
tq_rxrsp_dbidresp[L2_TQ_SIZE-1:0] |
tq_rxrsp_dbidrespord[L2_TQ_SIZE-1:0] |
tq_rxrsp_comp[L2_TQ_SIZE-1:0] |
tq_rxrsp_compdbidresp[L2_TQ_SIZE-1:0] )) |
({L2_TQ_SIZE{tq_dev_nr[i] & (vmid_q[i][6:0]==devicenr_txreq_token_q[6:0])}} & tq_dev_nr[L2_TQ_SIZE-1:0]) |
({L2_TQ_SIZE{tq_dvmsync[i]}} & ( tq_rxrsp_comp[L2_TQ_SIZE-1:0] |
({L2_TQ_SIZE{~(| l2b_any_ls_tlbi_ici_txreq_from_other_bank_q[2:0])}} & tq_dvmsync[L2_TQ_SIZE-1:0]) ));拆开看,第一种规则:普通 cacheable 访存操作
({L2_TQ_SIZE{~tq_dev_nc[i]}} & ( rxdat_flit_valid[L2_TQ_SIZE-1:0] |
(tq_rxrsp_dbidrespord[L2_TQ_SIZE-1:0] & ~needs_compcmo_q[L2_TQ_SIZE-1:0]) |
(tq_rxrsp_comp[L2_TQ_SIZE-1:0] & ~needs_compcmo_q[L2_TQ_SIZE-1:0]) |
(tq_rxrsp_compdbidresp[L2_TQ_SIZE-1:0] & ~needs_compcmo_q[L2_TQ_SIZE-1:0]) |
(tq_rxrsp_comppersist[L2_TQ_SIZE-1:0] & ~needs_compcmo_q[L2_TQ_SIZE-1:0]) |
(tq_rxrsp_compcmo[L2_TQ_SIZE-1:0] & needs_compcmo_q[L2_TQ_SIZE-1:0] & ~tq_needs_txreq[L2_TQ_SIZE-1:0]) |
(tq_rxrsp_comppersist[L2_TQ_SIZE-1:0] & needs_compcmo_q[L2_TQ_SIZE-1:0] & ~tq_needs_txreq[L2_TQ_SIZE-1:0]) )) |如果后续事务 i 是普通内存访问,它主要是在等前序事务 j 达到“全局可见(Globally Observed)”:
- 如果
j是读:只要收到数据 flit (rxdat_flit_valid),立刻解锁(CompData 走的数据通道)。 - 如果
j是普通的写:只要收到Comp、DBIDRespOrd或CompDBIDResp等代表排序完成的响应,立刻解锁。 - 如果
j是缓存维护操作 (needs_compcmo_q[j] == 1):必须收到专属的CompCMO且自己不再发送请求时,才解锁。
第二种规则:当 i 是 Device / Non-cacheable 强保序访存时
({L2_TQ_SIZE{tq_dev_nc[i] & ~tq_dvmsync[i]}} & ( tq_rxrsp_readreceipt[L2_TQ_SIZE-1:0] |
rxdat_flit_valid[L2_TQ_SIZE-1:0] |
tq_rxrsp_dbidresp[L2_TQ_SIZE-1:0] |
tq_rxrsp_dbidrespord[L2_TQ_SIZE-1:0] |
tq_rxrsp_comp[L2_TQ_SIZE-1:0] |
tq_rxrsp_compdbidresp[L2_TQ_SIZE-1:0] )) |Device 类型的访问通常受 DMB/DSB 的强约束。如果事务 i 是一条 Device/NC 访存,它必须乖乖等前面的事务 j 给出确切的保序答复:
- 如果
j是一条普通写,等Comp。 - 如果
j是一条读,等真实数据rxdat_flit_valid。 - 高亮部分:如果
j也是一条强保序 NC 读,只要收到了tq_rxrsp_readreceipt,j对i的依赖就提前解除了!(这也是我们上文详细讨论的优化点)。
第三种规则:对于极严格的非宽松设备内存 (nGnRnE) 发送令牌机制
({L2_TQ_SIZE{tq_dev_nr[i] & (vmid_q[i][6:0]==devicenr_txreq_token_q[6:0])}} & tq_dev_nr[L2_TQ_SIZE-1:0]) |tq_dev_nr (Non-Relaxed) 指的是 nGnRnE 这种对执行顺序极其苛刻的设备内存。为了防止队列头部阻塞,或者为了强行串行化发送,RTL 使用了一个 Token (令牌) 机制。如果 i 拿到了 Token,它就可以直接无视前序其他 tq_dev_nr 类型的 j 所造成的依赖。
第四种规则:当 i 是 DVM Sync 屏障指令时
({L2_TQ_SIZE{tq_dvmsync[i]}} & ( tq_rxrsp_comp[L2_TQ_SIZE-1:0] |
({L2_TQ_SIZE{~(| l2b_any_ls_tlbi_ici_txreq_from_other_bank_q[2:0])}} & tq_dvmsync[L2_TQ_SIZE-1:0]) ));DVMSync 是 ARM 架构中用来同步 TLBI(TLB 刷新)等分布式虚拟内存操作的屏障级消息。
- 如果
i是DVMSync,它要等前面的事务j收到Comp。 - 如果是两个连续的
DVMSync(j也是DVMSync),只要当前没有其他 Bank 发来的活跃请求,也可以安全解锁依赖。
以写指令为例
下面以一个执行一行简单的 x=1 为例进行说明:
因为 X = 1 通常是对某个 4 字节或 8 字节变量的“部分缓存行写入(Partial cache line write)”,系统必须确保在修改数据前,该核心拥有该缓存行的唯一权限(Unique),并且拥有该缓存行的最新数据(Data)。
执行 x=1 可分为三种最常见的初始状态。
场景一:缓存未命中(初始状态为 Invalid,I 态)
此时 Core 1 既没有数据,也没有权限。它必须发起 ReadUnique 事务来获取数据并作废其他核心的副本。这也是我们在上一个 Consistency 例子中假设的场景。
通信过程(以存在其他共享者 RN-F2 为例):
- REQ 通道 (RN-F1 -> HN-F): RN-F1 发送
ReadUnique请求。 - SNP 通道 (HN-F -> RN-F2): HN-F 发现该地址在 RN-F2 中处于 S 态,发送无效化监听,例如
SnpUnique(或符合单副本转发条件时的SnpUniqueFwd)。 - RSP 通道 (RN-F2 -> HN-F): RN-F2 将自己的缓存行更新为 Invalid (I),并向 HN-F 回复
SnpResp_I。 - DAT 通道 (HN-F -> RN-F1): HN-F 收集完监听确认后,将最新的数据通过
CompData_UC或CompData_UD_PD发送给 RN-F1。(注:收到此响应即代表 X=1 的前置准备已完成,具备了全局可见性边界)。 - CPU 内部动作: RN-F1 拿到数据并进入
UC(Unique Clean) 态后,CPU 流水线将1写入缓存行的对应字节。此时缓存行状态静默转换为UD(Unique Dirty)。 - RSP 通道 (RN-F1 -> HN-F): 由于
ReadUnique要求完成确认,RN-F1 发送CompAck给 HN-F,彻底结束该事务,HN-F 释放该地址的 Tracker 资源。
场景二:缓存命中但为共享态(初始状态为 Shared Clean,SC 态)
此时 Core 1 已经拥有正确的最新数据,但没有独占写入权限。为了不浪费带宽去传输无用的数据,它会发起无数据传输(Dataless)的 CleanUnique 事务。
通信过程:
- REQ 通道 (RN-F1 -> HN-F): RN-F1 发送
CleanUnique请求。 - SNP 通道 (HN-F -> RN-F2): HN-F 向其他拥有副本的节点发送
SnpCleanInvalid监听请求。 - RSP 通道 (RN-F2 -> HN-F): RN-F2 作废本地副本,回复
SnpResp_I。 - RSP 通道 (HN-F -> RN-F1): HN-F 回复
Comp_UC给 RN-F1(这只是一个权限升级的完成响应,没有数据 Payload)。 - CPU 内部动作: RN-F1 的状态从
SC升级为UC。随后 CPU 将1写入,状态变为UD。 - RSP 通道 (RN-F1 -> HN-F): RN-F1 发送
CompAck结束事务。(注:如果 X=1 的操作恰好通过矢量指令覆盖了完整的 64 字节缓存行,则会使用 MakeUnique,它连“要求其他节点回写脏数据”的动作都省了,直接暴力作废其他副本 )。
场景三:缓存命中且为独占态(初始状态为 Unique Clean, UC 或 Unique Dirty, UD 态)
此时 Core 1 已经拥有数据的唯一所有权,系统中不存在任何其他副本。
通信过程:
- 零消息通信:根据 CHI 协议的缓存状态模型,如果缓存行已经是 Unique 状态,请求节点可以随意更改缓存行的值,无需通知系统中的任何其他组件。
- CPU 内部动作: Core 1 直接将
1写入缓存。如果是UC态,则静默转换为UD态;如果是UD态,则保持UD态不变。这完美体现了 MESI/CHI 协议在连续写入同一变量时的极致效率。
回到前面的案例,跟场景一差不多,core1 已经收到了全局可见的信号,但 core2 的 X 还未收到 SnpUnique,这个时候,core2 执行一个 load X 指令,缓存直接命中,并不需要总线事务,没法依赖 HNF 维持可见性。
回到最初的问题
理解到 DMB 差不多,DSB 和 ISB 的苦活累活,大部分是交给了 Core 自己在内部默默抗下的,而不用到CHI 加塞。 核心一点,barrier在总线上的表现就是“收到上一笔ld/st请求的可见性响应(如CompData)后,再发出下一笔ld/st请求”。该案例可以用来展示,如果coherence、consistency有关系,该如何影响。另外,consistency也不一点非得要跟coherence 扯上关系,比如 load-load、store-store 乱序啥的实现不一定在 CHI 侧,可能更多的在 core 侧堆些结构就可以做到。
最后是本文想总结的:
1.Coherence 与 Consistency 的界限:Coherence 是负责让缓存副本最终长得一样,即使中间乱了,顶多是脏数据晚点刷出;但 Consistency 是神圣的“时间线”,一旦总线上的可见性(如 `CompData` 乱发)骗了 Barrier 信号,整个因果律就崩溃了。
2.总线 Barrier 的本质就是等回执:在 CHI 总线上,所谓的屏障并不是凭空立起一堵墙,它本质上就是死皮赖脸地等上一笔 Load/Store 的可见性回执(Observed)。只要回执没到手,下一笔请求就别想从本地发出去。
3.Consistency 并非都牵扯上总线:像 Load-Load、Store-Store 的乱序处理,更多的是在 Core 侧堆older 结果、年龄矩阵等来实现,并不一定都跟Coherence 直接相关;